Compare commits
165 Commits
LO_Module1
...
stream-hom
| Author | SHA1 | Date | |
|---|---|---|---|
| 744316473e | |||
| 6c045a2fa7 | |||
| ef377950c0 | |||
| 2990b7f14e | |||
| 44fc08d7db | |||
| 7caa2ff237 | |||
| 5801672ec8 | |||
| 4877ceb245 | |||
| 77340b1d79 | |||
| 177b1a8c18 | |||
| 5b71053758 | |||
| 9f8d5d12fe | |||
| ae86a2001d | |||
| 9d62b2cc61 | |||
| ab39fc3bcc | |||
| 5873a63ce9 | |||
| 89ea5e8bac | |||
| 0ac417886c | |||
| 35d50cec77 | |||
| be40774fdd | |||
| 1b516814d8 | |||
| eee41d9457 | |||
| eea2214132 | |||
| e9b3a17b9c | |||
| b94ab37921 | |||
| ae09f9b79d | |||
| f940e69e52 | |||
| a7caea6294 | |||
| 889b748f27 | |||
| 22134a14f1 | |||
| ee48f1d3f8 | |||
| 884f9f0350 | |||
| fe849fdf5c | |||
| e719405956 | |||
| 1ca12378ff | |||
| 624efa10ab | |||
| da36243d1c | |||
| ddc22c29ab | |||
| 19be2ed8f4 | |||
| db7f42d882 | |||
| 98f6a4df08 | |||
| 762b0ce4b9 | |||
| c9fae602b4 | |||
| 51d4241650 | |||
| 1dd47ba96c | |||
| a7393a4063 | |||
| 45991f4254 | |||
| b7a5d61406 | |||
| afdf9508e6 | |||
| b44834ff60 | |||
| c5a06cf150 | |||
| 770197cbe3 | |||
| cb874911ba | |||
| 782acf26ce | |||
| 1c7926a713 | |||
| 68f0e6cb53 | |||
| b17729fa9a | |||
| 7de55821ee | |||
| 8a56888246 | |||
| c3e5ef4518 | |||
| f31e2fe93a | |||
| 36c29eaf1b | |||
| 2ab335505c | |||
| 3fabb1cfda | |||
| baa2ea4cf7 | |||
| 4553062578 | |||
| d3dabf2b81 | |||
| 46e15f69e7 | |||
| d2e59f2350 | |||
| da6a842ee7 | |||
| d763f07395 | |||
| 427d17d012 | |||
| 51a9c95b7d | |||
| 6a2b86d8af | |||
| e659ff26b8 | |||
| 6bc22c63cf | |||
| 0f9b564bce | |||
| fe4419866d | |||
| 53b2676115 | |||
| c0c772b8ce | |||
| 4117ce9f5d | |||
| b1ad88253c | |||
| 049dd34c6c | |||
| 1efd2a236c | |||
| 72c4c821dc | |||
| 68e8e1a9cb | |||
| 261b50d042 | |||
| b269844ea3 | |||
| 35b99817dc | |||
| 78a5940578 | |||
| 13a7752e5e | |||
| 3af1021228 | |||
| f641f94a25 | |||
| 0563fb5ff7 | |||
| a64e90ac36 | |||
| e69c289b40 | |||
| 69bc9aec1b | |||
| fe176c1679 | |||
| d9cb16e282 | |||
| 6d2f1aa7e8 | |||
| 390b2f6994 | |||
| ef6791e1cf | |||
| 865849b0ef | |||
| 9249bfba29 | |||
| bb43aa52e4 | |||
| 9a6d7878fd | |||
| fe0b744ffe | |||
| dbe68cd993 | |||
| a00f31fb85 | |||
| 9882dd7411 | |||
| f46e0044b9 | |||
| 38087a646d | |||
| 4617e63ddd | |||
| 738c22f91b | |||
| d576cfb1c9 | |||
| af248385c0 | |||
| 7abbbde00e | |||
| dd84d736bc | |||
| 6ae0b18eea | |||
| e9c8748e29 | |||
| a6fda6d5ca | |||
| ee88d7f230 | |||
| 7a251b614b | |||
| b6901c05bf | |||
| 9e89d9849e | |||
| 2a59822b4a | |||
| f8221f25be | |||
| 9c219f7fdc | |||
| 5703a49efd | |||
| 7e2c7f94c4 | |||
| 20671b4b48 | |||
| 1d7f51ffaf | |||
| 43b2104fa9 | |||
| b11c9cb1e3 | |||
| ee0546ba0a | |||
| 1decc32b8d | |||
| 178fe94ed8 | |||
| a5e008b498 | |||
| ebcb10c8ab | |||
| cb55908a7c | |||
| 34a63cff05 | |||
| 3e247158a4 | |||
| 11c60f66c7 | |||
| 594faf0f32 | |||
| 2bb25463ea | |||
| bbe191aecc | |||
| fa39a9d342 | |||
| e4cb817399 | |||
| 5259facfb4 | |||
| 130a508a65 | |||
| dce01a2794 | |||
| 142b9f4ee4 | |||
| d18ceb6044 | |||
| 0e0aae68b4 | |||
| 468aacb1ef | |||
| 860833525a | |||
| 2418faf718 | |||
| 325131f959 | |||
| 8c455873fd | |||
| be68361c40 | |||
| bfef9aa2fb | |||
| 9847430ca7 | |||
| 960fed9828 | |||
| 3f5cefcdd7 | |||
| 57c7ce33f8 |
@ -113,6 +113,10 @@ $ aws s3 ls s3://nyc-tlc
|
||||
PRE trip data/
|
||||
```
|
||||
|
||||
You can refer the `data-loading-parquet.ipynb` and `data-loading-parquet.py` for code to handle both csv and paraquet files. (The lookup zones table which is needed later in this course is a csv file)
|
||||
> Note: You will need to install the `pyarrow` library. (add it to your Dockerfile)
|
||||
|
||||
|
||||
### pgAdmin
|
||||
|
||||
Running pgAdmin
|
||||
938
01-docker-terraform/2_docker_sql/data-loading-parquet.ipynb
Normal file
938
01-docker-terraform/2_docker_sql/data-loading-parquet.ipynb
Normal file
@ -0,0 +1,938 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "52bad16a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Data loading \n",
|
||||
"\n",
|
||||
"Here we will be using the ```.paraquet``` file we downloaded and do the following:\n",
|
||||
" - Check metadata and table datatypes of the paraquet file/table\n",
|
||||
" - Convert the paraquet file to pandas dataframe and check the datatypes. Additionally check the data dictionary to make sure you have the right datatypes in pandas, as pandas will automatically create the table in our database.\n",
|
||||
" - Generate the DDL CREATE statement from pandas for a sanity check.\n",
|
||||
" - Create a connection to our database using SQLAlchemy\n",
|
||||
" - Convert our huge paraquet file into a iterable that has batches of 100,000 rows and load it into our database."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "afef2456",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-12-03T23:55:14.141738Z",
|
||||
"start_time": "2023-12-03T23:55:14.124217Z"
|
||||
}
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import pandas as pd \n",
|
||||
"import pyarrow.parquet as pq\n",
|
||||
"from time import time"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "c750d1d4",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-12-03T02:54:01.925350Z",
|
||||
"start_time": "2023-12-03T02:54:01.661119Z"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"<pyarrow._parquet.FileMetaData object at 0x7fed89ffa540>\n",
|
||||
" created_by: parquet-cpp-arrow version 13.0.0\n",
|
||||
" num_columns: 19\n",
|
||||
" num_rows: 2846722\n",
|
||||
" num_row_groups: 3\n",
|
||||
" format_version: 2.6\n",
|
||||
" serialized_size: 6357"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Read metadata \n",
|
||||
"pq.read_metadata('yellow_tripdata_2023-09.parquet')"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "a970fcf0",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-12-03T23:28:08.411945Z",
|
||||
"start_time": "2023-12-03T23:28:08.177693Z"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"VendorID: int32\n",
|
||||
"tpep_pickup_datetime: timestamp[us]\n",
|
||||
"tpep_dropoff_datetime: timestamp[us]\n",
|
||||
"passenger_count: int64\n",
|
||||
"trip_distance: double\n",
|
||||
"RatecodeID: int64\n",
|
||||
"store_and_fwd_flag: large_string\n",
|
||||
"PULocationID: int32\n",
|
||||
"DOLocationID: int32\n",
|
||||
"payment_type: int64\n",
|
||||
"fare_amount: double\n",
|
||||
"extra: double\n",
|
||||
"mta_tax: double\n",
|
||||
"tip_amount: double\n",
|
||||
"tolls_amount: double\n",
|
||||
"improvement_surcharge: double\n",
|
||||
"total_amount: double\n",
|
||||
"congestion_surcharge: double\n",
|
||||
"Airport_fee: double"
|
||||
]
|
||||
},
|
||||
"execution_count": 41,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Read file, read the table from file and check schema\n",
|
||||
"file = pq.ParquetFile('yellow_tripdata_2023-09.parquet')\n",
|
||||
"table = file.read()\n",
|
||||
"table.schema"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "43f6ea7e",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-12-03T23:28:22.870376Z",
|
||||
"start_time": "2023-12-03T23:28:22.563414Z"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"<class 'pandas.core.frame.DataFrame'>\n",
|
||||
"RangeIndex: 2846722 entries, 0 to 2846721\n",
|
||||
"Data columns (total 19 columns):\n",
|
||||
" # Column Dtype \n",
|
||||
"--- ------ ----- \n",
|
||||
" 0 VendorID int32 \n",
|
||||
" 1 tpep_pickup_datetime datetime64[ns]\n",
|
||||
" 2 tpep_dropoff_datetime datetime64[ns]\n",
|
||||
" 3 passenger_count float64 \n",
|
||||
" 4 trip_distance float64 \n",
|
||||
" 5 RatecodeID float64 \n",
|
||||
" 6 store_and_fwd_flag object \n",
|
||||
" 7 PULocationID int32 \n",
|
||||
" 8 DOLocationID int32 \n",
|
||||
" 9 payment_type int64 \n",
|
||||
" 10 fare_amount float64 \n",
|
||||
" 11 extra float64 \n",
|
||||
" 12 mta_tax float64 \n",
|
||||
" 13 tip_amount float64 \n",
|
||||
" 14 tolls_amount float64 \n",
|
||||
" 15 improvement_surcharge float64 \n",
|
||||
" 16 total_amount float64 \n",
|
||||
" 17 congestion_surcharge float64 \n",
|
||||
" 18 Airport_fee float64 \n",
|
||||
"dtypes: datetime64[ns](2), float64(12), int32(3), int64(1), object(1)\n",
|
||||
"memory usage: 380.1+ MB\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Convert to pandas and check data \n",
|
||||
"df = table.to_pandas()\n",
|
||||
"df.info()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "ccf039a0",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"We need to first create the connection to our postgres database. We can feed the connection information to generate the CREATE SQL query for the specific server. SQLAlchemy supports a variety of servers."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "44e701ae",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-12-03T22:50:25.811951Z",
|
||||
"start_time": "2023-12-03T22:50:25.393987Z"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"<sqlalchemy.engine.base.Connection at 0x7fed98ea3190>"
|
||||
]
|
||||
},
|
||||
"execution_count": 28,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Create an open SQL database connection object or a SQLAlchemy connectable\n",
|
||||
"from sqlalchemy import create_engine\n",
|
||||
"\n",
|
||||
"engine = create_engine('postgresql://root:root@localhost:5432/ny_taxi')\n",
|
||||
"engine.connect()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "c96a1075",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-12-03T22:50:43.628727Z",
|
||||
"start_time": "2023-12-03T22:50:43.442337Z"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"CREATE TABLE yellow_taxi_data (\n",
|
||||
"\t\"VendorID\" INTEGER, \n",
|
||||
"\ttpep_pickup_datetime TIMESTAMP WITHOUT TIME ZONE, \n",
|
||||
"\ttpep_dropoff_datetime TIMESTAMP WITHOUT TIME ZONE, \n",
|
||||
"\tpassenger_count FLOAT(53), \n",
|
||||
"\ttrip_distance FLOAT(53), \n",
|
||||
"\t\"RatecodeID\" FLOAT(53), \n",
|
||||
"\tstore_and_fwd_flag TEXT, \n",
|
||||
"\t\"PULocationID\" INTEGER, \n",
|
||||
"\t\"DOLocationID\" INTEGER, \n",
|
||||
"\tpayment_type BIGINT, \n",
|
||||
"\tfare_amount FLOAT(53), \n",
|
||||
"\textra FLOAT(53), \n",
|
||||
"\tmta_tax FLOAT(53), \n",
|
||||
"\ttip_amount FLOAT(53), \n",
|
||||
"\ttolls_amount FLOAT(53), \n",
|
||||
"\timprovement_surcharge FLOAT(53), \n",
|
||||
"\ttotal_amount FLOAT(53), \n",
|
||||
"\tcongestion_surcharge FLOAT(53), \n",
|
||||
"\t\"Airport_fee\" FLOAT(53)\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Generate CREATE SQL statement from schema for validation\n",
|
||||
"print(pd.io.sql.get_schema(df, name='yellow_taxi_data', con=engine))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "eca7f32d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"Datatypes for the table looks good! Since we used paraquet file the datasets seem to have been preserved. You may have to convert some datatypes so it is always good to do this check."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "51a751ed",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Finally inserting data\n",
|
||||
"\n",
|
||||
"There are 2,846,722 rows in our dataset. We are going to use the ```parquet_file.iter_batches()``` function to create batches of 100,000, convert them into pandas and then load it into the postgres database."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "e20cec73",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-12-03T23:49:28.768786Z",
|
||||
"start_time": "2023-12-03T23:49:28.689732Z"
|
||||
},
|
||||
"scrolled": true
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/html": [
|
||||
"<div>\n",
|
||||
"<style scoped>\n",
|
||||
" .dataframe tbody tr th:only-of-type {\n",
|
||||
" vertical-align: middle;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" .dataframe tbody tr th {\n",
|
||||
" vertical-align: top;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" .dataframe thead th {\n",
|
||||
" text-align: right;\n",
|
||||
" }\n",
|
||||
"</style>\n",
|
||||
"<table border=\"1\" class=\"dataframe\">\n",
|
||||
" <thead>\n",
|
||||
" <tr style=\"text-align: right;\">\n",
|
||||
" <th></th>\n",
|
||||
" <th>VendorID</th>\n",
|
||||
" <th>tpep_pickup_datetime</th>\n",
|
||||
" <th>tpep_dropoff_datetime</th>\n",
|
||||
" <th>passenger_count</th>\n",
|
||||
" <th>trip_distance</th>\n",
|
||||
" <th>RatecodeID</th>\n",
|
||||
" <th>store_and_fwd_flag</th>\n",
|
||||
" <th>PULocationID</th>\n",
|
||||
" <th>DOLocationID</th>\n",
|
||||
" <th>payment_type</th>\n",
|
||||
" <th>fare_amount</th>\n",
|
||||
" <th>extra</th>\n",
|
||||
" <th>mta_tax</th>\n",
|
||||
" <th>tip_amount</th>\n",
|
||||
" <th>tolls_amount</th>\n",
|
||||
" <th>improvement_surcharge</th>\n",
|
||||
" <th>total_amount</th>\n",
|
||||
" <th>congestion_surcharge</th>\n",
|
||||
" <th>Airport_fee</th>\n",
|
||||
" </tr>\n",
|
||||
" </thead>\n",
|
||||
" <tbody>\n",
|
||||
" <tr>\n",
|
||||
" <th>0</th>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>2023-09-01 00:15:37</td>\n",
|
||||
" <td>2023-09-01 00:20:21</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>0.80</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>N</td>\n",
|
||||
" <td>163</td>\n",
|
||||
" <td>230</td>\n",
|
||||
" <td>2</td>\n",
|
||||
" <td>6.5</td>\n",
|
||||
" <td>3.5</td>\n",
|
||||
" <td>0.5</td>\n",
|
||||
" <td>0.00</td>\n",
|
||||
" <td>0.00</td>\n",
|
||||
" <td>1.0</td>\n",
|
||||
" <td>11.50</td>\n",
|
||||
" <td>2.5</td>\n",
|
||||
" <td>0.00</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>1</th>\n",
|
||||
" <td>2</td>\n",
|
||||
" <td>2023-09-01 00:18:40</td>\n",
|
||||
" <td>2023-09-01 00:30:28</td>\n",
|
||||
" <td>2</td>\n",
|
||||
" <td>2.34</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>N</td>\n",
|
||||
" <td>236</td>\n",
|
||||
" <td>233</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>14.2</td>\n",
|
||||
" <td>1.0</td>\n",
|
||||
" <td>0.5</td>\n",
|
||||
" <td>2.00</td>\n",
|
||||
" <td>0.00</td>\n",
|
||||
" <td>1.0</td>\n",
|
||||
" <td>21.20</td>\n",
|
||||
" <td>2.5</td>\n",
|
||||
" <td>0.00</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>2</th>\n",
|
||||
" <td>2</td>\n",
|
||||
" <td>2023-09-01 00:35:01</td>\n",
|
||||
" <td>2023-09-01 00:39:04</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>1.62</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>N</td>\n",
|
||||
" <td>162</td>\n",
|
||||
" <td>236</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>8.6</td>\n",
|
||||
" <td>1.0</td>\n",
|
||||
" <td>0.5</td>\n",
|
||||
" <td>2.00</td>\n",
|
||||
" <td>0.00</td>\n",
|
||||
" <td>1.0</td>\n",
|
||||
" <td>15.60</td>\n",
|
||||
" <td>2.5</td>\n",
|
||||
" <td>0.00</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>3</th>\n",
|
||||
" <td>2</td>\n",
|
||||
" <td>2023-09-01 00:45:45</td>\n",
|
||||
" <td>2023-09-01 00:47:37</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>0.74</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>N</td>\n",
|
||||
" <td>141</td>\n",
|
||||
" <td>229</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>5.1</td>\n",
|
||||
" <td>1.0</td>\n",
|
||||
" <td>0.5</td>\n",
|
||||
" <td>1.00</td>\n",
|
||||
" <td>0.00</td>\n",
|
||||
" <td>1.0</td>\n",
|
||||
" <td>11.10</td>\n",
|
||||
" <td>2.5</td>\n",
|
||||
" <td>0.00</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>4</th>\n",
|
||||
" <td>2</td>\n",
|
||||
" <td>2023-09-01 00:01:23</td>\n",
|
||||
" <td>2023-09-01 00:38:05</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>9.85</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>N</td>\n",
|
||||
" <td>138</td>\n",
|
||||
" <td>230</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>45.0</td>\n",
|
||||
" <td>6.0</td>\n",
|
||||
" <td>0.5</td>\n",
|
||||
" <td>17.02</td>\n",
|
||||
" <td>0.00</td>\n",
|
||||
" <td>1.0</td>\n",
|
||||
" <td>73.77</td>\n",
|
||||
" <td>2.5</td>\n",
|
||||
" <td>1.75</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>...</th>\n",
|
||||
" <td>...</td>\n",
|
||||
" <td>...</td>\n",
|
||||
" <td>...</td>\n",
|
||||
" <td>...</td>\n",
|
||||
" <td>...</td>\n",
|
||||
" <td>...</td>\n",
|
||||
" <td>...</td>\n",
|
||||
" <td>...</td>\n",
|
||||
" <td>...</td>\n",
|
||||
" <td>...</td>\n",
|
||||
" <td>...</td>\n",
|
||||
" <td>...</td>\n",
|
||||
" <td>...</td>\n",
|
||||
" <td>...</td>\n",
|
||||
" <td>...</td>\n",
|
||||
" <td>...</td>\n",
|
||||
" <td>...</td>\n",
|
||||
" <td>...</td>\n",
|
||||
" <td>...</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>99995</th>\n",
|
||||
" <td>2</td>\n",
|
||||
" <td>2023-09-02 09:55:17</td>\n",
|
||||
" <td>2023-09-02 10:01:45</td>\n",
|
||||
" <td>2</td>\n",
|
||||
" <td>1.48</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>N</td>\n",
|
||||
" <td>163</td>\n",
|
||||
" <td>164</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>9.3</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0.5</td>\n",
|
||||
" <td>2.66</td>\n",
|
||||
" <td>0.00</td>\n",
|
||||
" <td>1.0</td>\n",
|
||||
" <td>15.96</td>\n",
|
||||
" <td>2.5</td>\n",
|
||||
" <td>0.00</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>99996</th>\n",
|
||||
" <td>2</td>\n",
|
||||
" <td>2023-09-02 09:25:34</td>\n",
|
||||
" <td>2023-09-02 09:55:20</td>\n",
|
||||
" <td>3</td>\n",
|
||||
" <td>17.49</td>\n",
|
||||
" <td>2</td>\n",
|
||||
" <td>N</td>\n",
|
||||
" <td>132</td>\n",
|
||||
" <td>164</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>70.0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0.5</td>\n",
|
||||
" <td>24.28</td>\n",
|
||||
" <td>6.94</td>\n",
|
||||
" <td>1.0</td>\n",
|
||||
" <td>106.97</td>\n",
|
||||
" <td>2.5</td>\n",
|
||||
" <td>1.75</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>99997</th>\n",
|
||||
" <td>2</td>\n",
|
||||
" <td>2023-09-02 09:57:55</td>\n",
|
||||
" <td>2023-09-02 10:04:52</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>1.73</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>N</td>\n",
|
||||
" <td>164</td>\n",
|
||||
" <td>249</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>10.0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0.5</td>\n",
|
||||
" <td>2.80</td>\n",
|
||||
" <td>0.00</td>\n",
|
||||
" <td>1.0</td>\n",
|
||||
" <td>16.80</td>\n",
|
||||
" <td>2.5</td>\n",
|
||||
" <td>0.00</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>99998</th>\n",
|
||||
" <td>2</td>\n",
|
||||
" <td>2023-09-02 09:35:02</td>\n",
|
||||
" <td>2023-09-02 09:43:28</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>1.32</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>N</td>\n",
|
||||
" <td>113</td>\n",
|
||||
" <td>170</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>10.0</td>\n",
|
||||
" <td>0.0</td>\n",
|
||||
" <td>0.5</td>\n",
|
||||
" <td>4.20</td>\n",
|
||||
" <td>0.00</td>\n",
|
||||
" <td>1.0</td>\n",
|
||||
" <td>18.20</td>\n",
|
||||
" <td>2.5</td>\n",
|
||||
" <td>0.00</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>99999</th>\n",
|
||||
" <td>2</td>\n",
|
||||
" <td>2023-09-02 09:46:09</td>\n",
|
||||
" <td>2023-09-02 10:03:58</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>8.79</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>N</td>\n",
|
||||
" <td>138</td>\n",
|
||||
" <td>170</td>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>35.9</td>\n",
|
||||
" <td>5.0</td>\n",
|
||||
" <td>0.5</td>\n",
|
||||
" <td>10.37</td>\n",
|
||||
" <td>6.94</td>\n",
|
||||
" <td>1.0</td>\n",
|
||||
" <td>63.96</td>\n",
|
||||
" <td>2.5</td>\n",
|
||||
" <td>1.75</td>\n",
|
||||
" </tr>\n",
|
||||
" </tbody>\n",
|
||||
"</table>\n",
|
||||
"<p>100000 rows × 19 columns</p>\n",
|
||||
"</div>"
|
||||
],
|
||||
"text/plain": [
|
||||
" VendorID tpep_pickup_datetime tpep_dropoff_datetime passenger_count \\\n",
|
||||
"0 1 2023-09-01 00:15:37 2023-09-01 00:20:21 1 \n",
|
||||
"1 2 2023-09-01 00:18:40 2023-09-01 00:30:28 2 \n",
|
||||
"2 2 2023-09-01 00:35:01 2023-09-01 00:39:04 1 \n",
|
||||
"3 2 2023-09-01 00:45:45 2023-09-01 00:47:37 1 \n",
|
||||
"4 2 2023-09-01 00:01:23 2023-09-01 00:38:05 1 \n",
|
||||
"... ... ... ... ... \n",
|
||||
"99995 2 2023-09-02 09:55:17 2023-09-02 10:01:45 2 \n",
|
||||
"99996 2 2023-09-02 09:25:34 2023-09-02 09:55:20 3 \n",
|
||||
"99997 2 2023-09-02 09:57:55 2023-09-02 10:04:52 1 \n",
|
||||
"99998 2 2023-09-02 09:35:02 2023-09-02 09:43:28 1 \n",
|
||||
"99999 2 2023-09-02 09:46:09 2023-09-02 10:03:58 1 \n",
|
||||
"\n",
|
||||
" trip_distance RatecodeID store_and_fwd_flag PULocationID \\\n",
|
||||
"0 0.80 1 N 163 \n",
|
||||
"1 2.34 1 N 236 \n",
|
||||
"2 1.62 1 N 162 \n",
|
||||
"3 0.74 1 N 141 \n",
|
||||
"4 9.85 1 N 138 \n",
|
||||
"... ... ... ... ... \n",
|
||||
"99995 1.48 1 N 163 \n",
|
||||
"99996 17.49 2 N 132 \n",
|
||||
"99997 1.73 1 N 164 \n",
|
||||
"99998 1.32 1 N 113 \n",
|
||||
"99999 8.79 1 N 138 \n",
|
||||
"\n",
|
||||
" DOLocationID payment_type fare_amount extra mta_tax tip_amount \\\n",
|
||||
"0 230 2 6.5 3.5 0.5 0.00 \n",
|
||||
"1 233 1 14.2 1.0 0.5 2.00 \n",
|
||||
"2 236 1 8.6 1.0 0.5 2.00 \n",
|
||||
"3 229 1 5.1 1.0 0.5 1.00 \n",
|
||||
"4 230 1 45.0 6.0 0.5 17.02 \n",
|
||||
"... ... ... ... ... ... ... \n",
|
||||
"99995 164 1 9.3 0.0 0.5 2.66 \n",
|
||||
"99996 164 1 70.0 0.0 0.5 24.28 \n",
|
||||
"99997 249 1 10.0 0.0 0.5 2.80 \n",
|
||||
"99998 170 1 10.0 0.0 0.5 4.20 \n",
|
||||
"99999 170 1 35.9 5.0 0.5 10.37 \n",
|
||||
"\n",
|
||||
" tolls_amount improvement_surcharge total_amount \\\n",
|
||||
"0 0.00 1.0 11.50 \n",
|
||||
"1 0.00 1.0 21.20 \n",
|
||||
"2 0.00 1.0 15.60 \n",
|
||||
"3 0.00 1.0 11.10 \n",
|
||||
"4 0.00 1.0 73.77 \n",
|
||||
"... ... ... ... \n",
|
||||
"99995 0.00 1.0 15.96 \n",
|
||||
"99996 6.94 1.0 106.97 \n",
|
||||
"99997 0.00 1.0 16.80 \n",
|
||||
"99998 0.00 1.0 18.20 \n",
|
||||
"99999 6.94 1.0 63.96 \n",
|
||||
"\n",
|
||||
" congestion_surcharge Airport_fee \n",
|
||||
"0 2.5 0.00 \n",
|
||||
"1 2.5 0.00 \n",
|
||||
"2 2.5 0.00 \n",
|
||||
"3 2.5 0.00 \n",
|
||||
"4 2.5 1.75 \n",
|
||||
"... ... ... \n",
|
||||
"99995 2.5 0.00 \n",
|
||||
"99996 2.5 1.75 \n",
|
||||
"99997 2.5 0.00 \n",
|
||||
"99998 2.5 0.00 \n",
|
||||
"99999 2.5 1.75 \n",
|
||||
"\n",
|
||||
"[100000 rows x 19 columns]"
|
||||
]
|
||||
},
|
||||
"execution_count": 66,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"#This part is for testing\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# Creating batches of 100,000 for the paraquet file\n",
|
||||
"batches_iter = file.iter_batches(batch_size=100000)\n",
|
||||
"batches_iter\n",
|
||||
"\n",
|
||||
"# Take the first batch for testing\n",
|
||||
"df = next(batches_iter).to_pandas()\n",
|
||||
"df\n",
|
||||
"\n",
|
||||
"# Creating just the table in postgres\n",
|
||||
"#df.head(0).to_sql(name='ny_taxi_data',con=engine, if_exists='replace')"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "7fdda025",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-12-04T00:08:07.651559Z",
|
||||
"start_time": "2023-12-04T00:02:35.940526Z"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"inserting batch 1...\n",
|
||||
"inserted! time taken 12.916 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 2...\n",
|
||||
"inserted! time taken 11.782 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 3...\n",
|
||||
"inserted! time taken 11.854 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 4...\n",
|
||||
"inserted! time taken 11.753 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 5...\n",
|
||||
"inserted! time taken 12.034 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 6...\n",
|
||||
"inserted! time taken 11.742 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 7...\n",
|
||||
"inserted! time taken 12.351 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 8...\n",
|
||||
"inserted! time taken 11.052 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 9...\n",
|
||||
"inserted! time taken 12.167 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 10...\n",
|
||||
"inserted! time taken 12.335 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 11...\n",
|
||||
"inserted! time taken 11.375 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 12...\n",
|
||||
"inserted! time taken 10.937 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 13...\n",
|
||||
"inserted! time taken 12.208 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 14...\n",
|
||||
"inserted! time taken 11.542 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 15...\n",
|
||||
"inserted! time taken 11.460 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 16...\n",
|
||||
"inserted! time taken 11.868 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 17...\n",
|
||||
"inserted! time taken 11.162 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 18...\n",
|
||||
"inserted! time taken 11.774 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 19...\n",
|
||||
"inserted! time taken 11.772 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 20...\n",
|
||||
"inserted! time taken 10.971 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 21...\n",
|
||||
"inserted! time taken 11.483 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 22...\n",
|
||||
"inserted! time taken 11.718 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 23...\n",
|
||||
"inserted! time taken 11.628 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 24...\n",
|
||||
"inserted! time taken 11.622 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 25...\n",
|
||||
"inserted! time taken 11.236 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 26...\n",
|
||||
"inserted! time taken 11.258 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 27...\n",
|
||||
"inserted! time taken 11.746 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 28...\n",
|
||||
"inserted! time taken 10.031 seconds.\n",
|
||||
"\n",
|
||||
"inserting batch 29...\n",
|
||||
"inserted! time taken 5.077 seconds.\n",
|
||||
"\n",
|
||||
"Completed! Total time taken was 331.674 seconds for 29 batches.\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Insert values into the table \n",
|
||||
"t_start = time()\n",
|
||||
"count = 0\n",
|
||||
"for batch in file.iter_batches(batch_size=100000):\n",
|
||||
" count+=1\n",
|
||||
" batch_df = batch.to_pandas()\n",
|
||||
" print(f'inserting batch {count}...')\n",
|
||||
" b_start = time()\n",
|
||||
" \n",
|
||||
" batch_df.to_sql(name='ny_taxi_data',con=engine, if_exists='append')\n",
|
||||
" b_end = time()\n",
|
||||
" print(f'inserted! time taken {b_end-b_start:10.3f} seconds.\\n')\n",
|
||||
" \n",
|
||||
"t_end = time() \n",
|
||||
"print(f'Completed! Total time taken was {t_end-t_start:10.3f} seconds for {count} batches.') "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "a7c102be",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Extra bit\n",
|
||||
"\n",
|
||||
"While trying to do the SQL Refresher, there was a need to add a lookup zones table but the file is in ```.csv``` format. \n",
|
||||
"\n",
|
||||
"Let's code to handle both ```.csv``` and ```.paraquet``` files!"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "a643d171",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-12-05T20:59:29.236458Z",
|
||||
"start_time": "2023-12-05T20:59:28.551221Z"
|
||||
}
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from time import time\n",
|
||||
"import pandas as pd \n",
|
||||
"import pyarrow.parquet as pq\n",
|
||||
"from sqlalchemy import create_engine"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "62c9040a",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-12-05T21:18:11.346552Z",
|
||||
"start_time": "2023-12-05T21:18:11.337475Z"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"'yellow_tripdata_2023-09.parquet'"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"url = 'https://d37ci6vzurychx.cloudfront.net/misc/taxi+_zone_lookup.csv'\n",
|
||||
"url = 'https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2023-09.parquet'\n",
|
||||
"\n",
|
||||
"file_name = url.rsplit('/', 1)[-1].strip()\n",
|
||||
"file_name"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "e495fa96",
|
||||
"metadata": {
|
||||
"ExecuteTime": {
|
||||
"end_time": "2023-12-05T21:18:33.001561Z",
|
||||
"start_time": "2023-12-05T21:18:32.844872Z"
|
||||
}
|
||||
},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"oh yea\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"if '.csv' in file_name:\n",
|
||||
" print('yay') \n",
|
||||
" df = pd.read_csv(file_name, nrows=10)\n",
|
||||
" df_iter = pd.read_csv(file_name, iterator=True, chunksize=100000)\n",
|
||||
"elif '.parquet' in file_name:\n",
|
||||
" print('oh yea')\n",
|
||||
" file = pq.ParquetFile(file_name)\n",
|
||||
" df = next(file.iter_batches(batch_size=10)).to_pandas()\n",
|
||||
" df_iter = file.iter_batches(batch_size=100000)\n",
|
||||
"else: \n",
|
||||
" print('Error. Only .csv or .parquet files allowed.')\n",
|
||||
" sys.exit() "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "7556748f",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"This code is a rough code and seems to be working. The cleaned up version will be in `data-loading-parquet.py` file."
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"hide_input": false,
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.9.5"
|
||||
},
|
||||
"varInspector": {
|
||||
"cols": {
|
||||
"lenName": 16,
|
||||
"lenType": 16,
|
||||
"lenVar": 40
|
||||
},
|
||||
"kernels_config": {
|
||||
"python": {
|
||||
"delete_cmd_postfix": "",
|
||||
"delete_cmd_prefix": "del ",
|
||||
"library": "var_list.py",
|
||||
"varRefreshCmd": "print(var_dic_list())"
|
||||
},
|
||||
"r": {
|
||||
"delete_cmd_postfix": ") ",
|
||||
"delete_cmd_prefix": "rm(",
|
||||
"library": "var_list.r",
|
||||
"varRefreshCmd": "cat(var_dic_list()) "
|
||||
}
|
||||
},
|
||||
"types_to_exclude": [
|
||||
"module",
|
||||
"function",
|
||||
"builtin_function_or_method",
|
||||
"instance",
|
||||
"_Feature"
|
||||
],
|
||||
"window_display": false
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
86
01-docker-terraform/2_docker_sql/data-loading-parquet.py
Normal file
86
01-docker-terraform/2_docker_sql/data-loading-parquet.py
Normal file
@ -0,0 +1,86 @@
|
||||
#Cleaned up version of data-loading.ipynb
|
||||
import argparse, os, sys
|
||||
from time import time
|
||||
import pandas as pd
|
||||
import pyarrow.parquet as pq
|
||||
from sqlalchemy import create_engine
|
||||
|
||||
|
||||
def main(params):
|
||||
user = params.user
|
||||
password = params.password
|
||||
host = params.host
|
||||
port = params.port
|
||||
db = params.db
|
||||
tb = params.tb
|
||||
url = params.url
|
||||
|
||||
# Get the name of the file from url
|
||||
file_name = url.rsplit('/', 1)[-1].strip()
|
||||
print(f'Downloading {file_name} ...')
|
||||
# Download file from url
|
||||
os.system(f'curl {url.strip()} -o {file_name}')
|
||||
print('\n')
|
||||
|
||||
# Create SQL engine
|
||||
engine = create_engine(f'postgresql://{user}:{password}@{host}:{port}/{db}')
|
||||
|
||||
# Read file based on csv or parquet
|
||||
if '.csv' in file_name:
|
||||
df = pd.read_csv(file_name, nrows=10)
|
||||
df_iter = pd.read_csv(file_name, iterator=True, chunksize=100000)
|
||||
elif '.parquet' in file_name:
|
||||
file = pq.ParquetFile(file_name)
|
||||
df = next(file.iter_batches(batch_size=10)).to_pandas()
|
||||
df_iter = file.iter_batches(batch_size=100000)
|
||||
else:
|
||||
print('Error. Only .csv or .parquet files allowed.')
|
||||
sys.exit()
|
||||
|
||||
|
||||
# Create the table
|
||||
df.head(0).to_sql(name=tb, con=engine, if_exists='replace')
|
||||
|
||||
|
||||
# Insert values
|
||||
t_start = time()
|
||||
count = 0
|
||||
for batch in df_iter:
|
||||
count+=1
|
||||
|
||||
if '.parquet' in file_name:
|
||||
batch_df = batch.to_pandas()
|
||||
else:
|
||||
batch_df = batch
|
||||
|
||||
print(f'inserting batch {count}...')
|
||||
|
||||
b_start = time()
|
||||
batch_df.to_sql(name=tb, con=engine, if_exists='append')
|
||||
b_end = time()
|
||||
|
||||
print(f'inserted! time taken {b_end-b_start:10.3f} seconds.\n')
|
||||
|
||||
t_end = time()
|
||||
print(f'Completed! Total time taken was {t_end-t_start:10.3f} seconds for {count} batches.')
|
||||
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
#Parsing arguments
|
||||
parser = argparse.ArgumentParser(description='Loading data from .paraquet file link to a Postgres datebase.')
|
||||
|
||||
parser.add_argument('--user', help='Username for Postgres.')
|
||||
parser.add_argument('--password', help='Password to the username for Postgres.')
|
||||
parser.add_argument('--host', help='Hostname for Postgres.')
|
||||
parser.add_argument('--port', help='Port for Postgres connection.')
|
||||
parser.add_argument('--db', help='Databse name for Postgres')
|
||||
parser.add_argument('--tb', help='Destination table name for Postgres.')
|
||||
parser.add_argument('--url', help='URL for .paraquet file.')
|
||||
|
||||
args = parser.parse_args()
|
||||
main(args)
|
||||
|
||||
|
||||
|
||||
|
||||
211
01-docker-terraform/README.md
Normal file
211
01-docker-terraform/README.md
Normal file
@ -0,0 +1,211 @@
|
||||
# Introduction
|
||||
|
||||
* [](https://www.youtube.com/watch?v=AtRhA-NfS24&list=PL3MmuxUbc_hKihpnNQ9qtTmWYy26bPrSb&index=3)
|
||||
* [Slides](https://www.slideshare.net/AlexeyGrigorev/data-engineering-zoomcamp-introduction)
|
||||
* Overview of [Architecture](https://github.com/DataTalksClub/data-engineering-zoomcamp#overview), [Technologies](https://github.com/DataTalksClub/data-engineering-zoomcamp#technologies) & [Pre-Requisites](https://github.com/DataTalksClub/data-engineering-zoomcamp#prerequisites)
|
||||
|
||||
|
||||
We suggest watching videos in the same order as in this document.
|
||||
|
||||
The last video (setting up the environment) is optional, but you can check it earlier
|
||||
if you have troubles setting up the environment and following along with the videos.
|
||||
|
||||
|
||||
# Docker + Postgres
|
||||
|
||||
[Code](2_docker_sql)
|
||||
|
||||
## :movie_camera: Introduction to Docker
|
||||
|
||||
[](https://youtu.be/EYNwNlOrpr0&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=4)
|
||||
|
||||
* Why do we need Docker
|
||||
* Creating a simple "data pipeline" in Docker
|
||||
|
||||
|
||||
## :movie_camera: Ingesting NY Taxi Data to Postgres
|
||||
|
||||
[](https://youtu.be/2JM-ziJt0WI&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=5)
|
||||
|
||||
* Running Postgres locally with Docker
|
||||
* Using `pgcli` for connecting to the database
|
||||
* Exploring the NY Taxi dataset
|
||||
* Ingesting the data into the database
|
||||
|
||||
> [!TIP]
|
||||
>if you have problems with `pgcli`, check this video for an alternative way to connect to your database in jupyter notebook and pandas.
|
||||
>
|
||||
> [](https://youtu.be/3IkfkTwqHx4&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=6)
|
||||
|
||||
|
||||
## :movie_camera: Connecting pgAdmin and Postgres
|
||||
|
||||
[](https://youtu.be/hCAIVe9N0ow&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=7)
|
||||
|
||||
* The pgAdmin tool
|
||||
* Docker networks
|
||||
|
||||
|
||||
> [!IMPORTANT]
|
||||
>The UI for PgAdmin 4 has changed, please follow the below steps for creating a server:
|
||||
>
|
||||
>* After login to PgAdmin, right click Servers in the left sidebar.
|
||||
>* Click on Register.
|
||||
>* Click on Server.
|
||||
>* The remaining steps to create a server are the same as in the videos.
|
||||
|
||||
|
||||
## :movie_camera: Putting the ingestion script into Docker
|
||||
|
||||
[](https://youtu.be/B1WwATwf-vY&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=8)
|
||||
|
||||
* Converting the Jupyter notebook to a Python script
|
||||
* Parametrizing the script with argparse
|
||||
* Dockerizing the ingestion script
|
||||
|
||||
## :movie_camera: Running Postgres and pgAdmin with Docker-Compose
|
||||
|
||||
[](https://youtu.be/hKI6PkPhpa0&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=9)
|
||||
|
||||
* Why do we need Docker-compose
|
||||
* Docker-compose YAML file
|
||||
* Running multiple containers with `docker-compose up`
|
||||
|
||||
## :movie_camera: SQL refresher
|
||||
|
||||
[](https://youtu.be/QEcps_iskgg&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=10)
|
||||
|
||||
* Adding the Zones table
|
||||
* Inner joins
|
||||
* Basic data quality checks
|
||||
* Left, Right and Outer joins
|
||||
* Group by
|
||||
|
||||
## :movie_camera: Optional: Docker Networking and Port Mapping
|
||||
|
||||
> [!TIP]
|
||||
> Optional: If you have some problems with docker networking, check **Port Mapping and Networks in Docker video**.
|
||||
|
||||
[](https://youtu.be/tOr4hTsHOzU&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=5)
|
||||
|
||||
* Docker networks
|
||||
* Port forwarding to the host environment
|
||||
* Communicating between containers in the network
|
||||
* `.dockerignore` file
|
||||
|
||||
## :movie_camera: Optional: Walk-Through on WSL
|
||||
|
||||
> [!TIP]
|
||||
> Optional: If you are willing to do the steps from "Ingesting NY Taxi Data to Postgres" till "Running Postgres and pgAdmin with Docker-Compose" with Windows Subsystem Linux please check **Docker Module Walk-Through on WSL**.
|
||||
|
||||
[](https://youtu.be/Mv4zFm2AwzQ&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=33)
|
||||
|
||||
|
||||
# GCP
|
||||
|
||||
## :movie_camera: Introduction to GCP (Google Cloud Platform)
|
||||
|
||||
[](https://youtu.be/18jIzE41fJ4&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=3)
|
||||
|
||||
# Terraform
|
||||
|
||||
[Code](1_terraform_gcp)
|
||||
|
||||
## :movie_camera: Introduction Terraform: Concepts and Overview, a primer
|
||||
|
||||
[](https://youtu.be/s2bOYDCKl_M&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=11)
|
||||
|
||||
* [Companion Notes](1_terraform_gcp)
|
||||
|
||||
## :movie_camera: Terraform Basics: Simple one file Terraform Deployment
|
||||
|
||||
[](https://youtu.be/Y2ux7gq3Z0o&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=12)
|
||||
|
||||
* [Companion Notes](1_terraform_gcp)
|
||||
|
||||
## :movie_camera: Deployment with a Variables File
|
||||
|
||||
[](https://youtu.be/PBi0hHjLftk&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=13)
|
||||
|
||||
* [Companion Notes](1_terraform_gcp)
|
||||
|
||||
## Configuring terraform and GCP SDK on Windows
|
||||
|
||||
* [Instructions](1_terraform_gcp/windows.md)
|
||||
|
||||
|
||||
# Environment setup
|
||||
|
||||
For the course you'll need:
|
||||
|
||||
* Python 3 (e.g. installed with Anaconda)
|
||||
* Google Cloud SDK
|
||||
* Docker with docker-compose
|
||||
* Terraform
|
||||
* Git account
|
||||
|
||||
> [!NOTE]
|
||||
>If you have problems setting up the environment, you can check these videos.
|
||||
>
|
||||
>If you already have a working coding environment on local machine, these are optional. And only need to select one method. But if you have time to learn it now, these would be helpful if the local environment suddenly do not work one day.
|
||||
|
||||
## :movie_camera: GCP Cloud VM
|
||||
|
||||
### Setting up the environment on cloud VM
|
||||
[](https://youtu.be/ae-CV2KfoN0&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=14)
|
||||
|
||||
* Generating SSH keys
|
||||
* Creating a virtual machine on GCP
|
||||
* Connecting to the VM with SSH
|
||||
* Installing Anaconda
|
||||
* Installing Docker
|
||||
* Creating SSH `config` file
|
||||
* Accessing the remote machine with VS Code and SSH remote
|
||||
* Installing docker-compose
|
||||
* Installing pgcli
|
||||
* Port-forwarding with VS code: connecting to pgAdmin and Jupyter from the local computer
|
||||
* Installing Terraform
|
||||
* Using `sftp` for putting the credentials to the remote machine
|
||||
* Shutting down and removing the instance
|
||||
|
||||
## :movie_camera: GitHub Codespaces
|
||||
|
||||
### Preparing the environment with GitHub Codespaces
|
||||
|
||||
[](https://youtu.be/XOSUt8Ih3zA&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=15)
|
||||
|
||||
# Homework
|
||||
|
||||
* [Homework](../cohorts/2024/01-docker-terraform/homework.md)
|
||||
|
||||
|
||||
# Community notes
|
||||
|
||||
Did you take notes? You can share them here
|
||||
|
||||
* [Notes from Alvaro Navas](https://github.com/ziritrion/dataeng-zoomcamp/blob/main/notes/1_intro.md)
|
||||
* [Notes from Abd](https://itnadigital.notion.site/Week-1-Introduction-f18de7e69eb4453594175d0b1334b2f4)
|
||||
* [Notes from Aaron](https://github.com/ABZ-Aaron/DataEngineerZoomCamp/blob/master/week_1_basics_n_setup/README.md)
|
||||
* [Notes from Faisal](https://github.com/FaisalMohd/data-engineering-zoomcamp/blob/main/week_1_basics_n_setup/Notes/DE%20Zoomcamp%20Week-1.pdf)
|
||||
* [Michael Harty's Notes](https://github.com/mharty3/data_engineering_zoomcamp_2022/tree/main/week01)
|
||||
* [Blog post from Isaac Kargar](https://kargarisaac.github.io/blog/data%20engineering/jupyter/2022/01/18/data-engineering-w1.html)
|
||||
* [Handwritten Notes By Mahmoud Zaher](https://github.com/zaherweb/DataEngineering/blob/master/week%201.pdf)
|
||||
* [Notes from Candace Williams](https://teacherc.github.io/data-engineering/2023/01/18/zoomcamp1.html)
|
||||
* [Notes from Marcos Torregrosa](https://www.n4gash.com/2023/data-engineering-zoomcamp-semana-1/)
|
||||
* [Notes from Vincenzo Galante](https://binchentso.notion.site/Data-Talks-Club-Data-Engineering-Zoomcamp-8699af8e7ff94ec49e6f9bdec8eb69fd)
|
||||
* [Notes from Victor Padilha](https://github.com/padilha/de-zoomcamp/tree/master/week1)
|
||||
* [Notes from froukje](https://github.com/froukje/de-zoomcamp/blob/main/week_1_basics_n_setup/notes/notes_week_01.md)
|
||||
* [Notes from adamiaonr](https://github.com/adamiaonr/data-engineering-zoomcamp/blob/main/week_1_basics_n_setup/2_docker_sql/NOTES.md)
|
||||
* [Notes from Xia He-Bleinagel](https://xiahe-bleinagel.com/2023/01/week-1-data-engineering-zoomcamp-notes/)
|
||||
* [Notes from Balaji](https://github.com/Balajirvp/DE-Zoomcamp/blob/main/Week%201/Detailed%20Week%201%20Notes.ipynb)
|
||||
* [Notes from Erik](https://twitter.com/ehub96/status/1621351266281730049)
|
||||
* [Notes by Alain Boisvert](https://github.com/boisalai/de-zoomcamp-2023/blob/main/week1.md)
|
||||
* Notes on [Docker, Docker Compose, and setting up a proper Python environment](https://medium.com/@verazabeida/zoomcamp-2023-week-1-f4f94cb360ae), by Vera
|
||||
* [Setting up the development environment on Google Virtual Machine](https://itsadityagupta.hashnode.dev/setting-up-the-development-environment-on-google-virtual-machine), blog post by Aditya Gupta
|
||||
* [Notes from Zharko Cekovski](https://www.zharconsulting.com/contents/data/data-engineering-bootcamp-2024/week-1-postgres-docker-and-ingestion-scripts/)
|
||||
* [2024 Module-01 Walkthough video by ellacharmed on youtube](https://youtu.be/VUZshlVAnk4)
|
||||
* [2024 Companion Module Walkthough slides by ellacharmed](https://github.com/ellacharmed/data-engineering-zoomcamp/blob/ella2024/cohorts/2024/01-docker-terraform/walkthrough-01.pdf)
|
||||
* [2024 Module-01 Environment setup video by ellacharmed on youtube](https://youtu.be/Zce_Hd37NGs)
|
||||
* [Docker Notes by Linda](https://github.com/inner-outer-space/de-zoomcamp-2024/blob/main/1a-docker_sql/readme.md) • [Terraform Notes by Linda](https://github.com/inner-outer-space/de-zoomcamp-2024/blob/main/1b-terraform_gcp/readme.md)
|
||||
* [Notes from Hammad Tariq](https://github.com/hamad-tariq/HammadTariq-ZoomCamp2024/blob/9c8b4908416eb8cade3d7ec220e7664c003e9b11/week_1_basics_n_setup/README.md)
|
||||
* Add your notes above this line
|
||||
191
02-workflow-orchestration/README.md
Normal file
191
02-workflow-orchestration/README.md
Normal file
@ -0,0 +1,191 @@
|
||||
> [!NOTE]
|
||||
>If you're looking for Airflow videos from the 2022 edition, check the [2022 cohort folder](../cohorts/2022/week_2_data_ingestion/).
|
||||
>
|
||||
>If you're looking for Prefect videos from the 2023 edition, check the [2023 cohort folder](../cohorts/2023/week_2_data_ingestion/).
|
||||
|
||||
# Week 2: Workflow Orchestration
|
||||
|
||||
Welcome to Week 2 of the Data Engineering Zoomcamp! 🚀😤 This week, we'll be covering workflow orchestration with Mage.
|
||||
|
||||
Mage is an open-source, hybrid framework for transforming and integrating data. ✨
|
||||
|
||||
This week, you'll learn how to use the Mage platform to author and share _magical_ data pipelines. This will all be covered in the course, but if you'd like to learn a bit more about Mage, check out our docs [here](https://docs.mage.ai/introduction/overview).
|
||||
|
||||
* [2.2.1 - 📯 Intro to Orchestration](#221----intro-to-orchestration)
|
||||
* [2.2.2 - 🧙♂️ Intro to Mage](#222---%EF%B8%8F-intro-to-mage)
|
||||
* [2.2.3 - 🐘 ETL: API to Postgres](#223----etl-api-to-postgres)
|
||||
* [2.2.4 - 🤓 ETL: API to GCS](#224----etl-api-to-gcs)
|
||||
* [2.2.5 - 🔍 ETL: GCS to BigQuery](#225----etl-gcs-to-bigquery)
|
||||
* [2.2.6 - 👨💻 Parameterized Execution](#226----parameterized-execution)
|
||||
* [2.2.7 - 🤖 Deployment (Optional)](#227----deployment-optional)
|
||||
* [2.2.8 - 🗒️ Homework](#228---️-homework)
|
||||
* [2.2.9 - 👣 Next Steps](#229----next-steps)
|
||||
|
||||
## 📕 Course Resources
|
||||
|
||||
### 2.2.1 - 📯 Intro to Orchestration
|
||||
|
||||
In this section, we'll cover the basics of workflow orchestration. We'll discuss what it is, why it's important, and how it can be used to build data pipelines.
|
||||
|
||||
Videos
|
||||
- 2.2.1a - What is Orchestration?
|
||||
|
||||
[](https://youtu.be/Li8-MWHhTbo&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=17)
|
||||
|
||||
Resources
|
||||
- [Slides](https://docs.google.com/presentation/d/17zSxG5Z-tidmgY-9l7Al1cPmz4Slh4VPK6o2sryFYvw/)
|
||||
|
||||
### 2.2.2 - 🧙♂️ Intro to Mage
|
||||
|
||||
In this section, we'll introduce the Mage platform. We'll cover what makes Mage different from other orchestrators, the fundamental concepts behind Mage, and how to get started. To cap it off, we'll spin Mage up via Docker 🐳 and run a simple pipeline.
|
||||
|
||||
Videos
|
||||
- 2.2.2a - What is Mage?
|
||||
|
||||
[](https://youtu.be/AicKRcK3pa4&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=18)
|
||||
|
||||
- 2.2.2b - Configuring Mage
|
||||
|
||||
[](https://youtu.be/tNiV7Wp08XE&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=19)
|
||||
|
||||
- 2.2.2c - A Simple Pipeline
|
||||
|
||||
[](https://youtu.be/stI-gg4QBnI&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=20)
|
||||
|
||||
Resources
|
||||
- [Getting Started Repo](https://github.com/mage-ai/mage-zoomcamp)
|
||||
- [Slides](https://docs.google.com/presentation/d/1y_5p3sxr6Xh1RqE6N8o2280gUzAdiic2hPhYUUD6l88/)
|
||||
|
||||
### 2.2.3 - 🐘 ETL: API to Postgres
|
||||
|
||||
Hooray! Mage is up and running. Now, let's build a _real_ pipeline. In this section, we'll build a simple ETL pipeline that loads data from an API into a Postgres database. Our database will be built using Docker— it will be running locally, but it's the same as if it were running in the cloud.
|
||||
|
||||
Videos
|
||||
- 2.2.3a - Configuring Postgres
|
||||
|
||||
[](https://youtu.be/pmhI-ezd3BE&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=21)
|
||||
|
||||
- 2.2.3b - Writing an ETL Pipeline : API to postgres
|
||||
|
||||
[](https://youtu.be/Maidfe7oKLs&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=22)
|
||||
|
||||
|
||||
### 2.2.4 - 🤓 ETL: API to GCS
|
||||
|
||||
Ok, so we've written data _locally_ to a database, but what about the cloud? In this tutorial, we'll walk through the process of using Mage to extract, transform, and load data from an API to Google Cloud Storage (GCS).
|
||||
|
||||
We'll cover both writing _partitioned_ and _unpartitioned_ data to GCS and discuss _why_ you might want to do one over the other. Many data teams start with extracting data from a source and writing it to a data lake _before_ loading it to a structured data source, like a database.
|
||||
|
||||
Videos
|
||||
- 2.2.4a - Configuring GCP
|
||||
|
||||
[](https://youtu.be/00LP360iYvE&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=23)
|
||||
|
||||
- 2.2.4b - Writing an ETL Pipeline : API to GCS
|
||||
|
||||
[](https://youtu.be/w0XmcASRUnc&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=24)
|
||||
|
||||
Resources
|
||||
- [DTC Zoomcamp GCP Setup](../01-docker-terraform/1_terraform_gcp/2_gcp_overview.md)
|
||||
|
||||
### 2.2.5 - 🔍 ETL: GCS to BigQuery
|
||||
|
||||
Now that we've written data to GCS, let's load it into BigQuery. In this section, we'll walk through the process of using Mage to load our data from GCS to BigQuery. This closely mirrors a very common data engineering workflow: loading data from a data lake into a data warehouse.
|
||||
|
||||
Videos
|
||||
- 2.2.5a - Writing an ETL Pipeline : GCS to BigQuery
|
||||
|
||||
[](https://youtu.be/JKp_uzM-XsM&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=25)
|
||||
|
||||
### 2.2.6 - 👨💻 Parameterized Execution
|
||||
|
||||
By now you're familiar with building pipelines, but what about adding parameters? In this video, we'll discuss some built-in runtime variables that exist in Mage and show you how to define your own! We'll also cover how to use these variables to parameterize your pipelines. Finally, we'll talk about what it means to *backfill* a pipeline and how to do it in Mage.
|
||||
|
||||
Videos
|
||||
- 2.2.6a - Parameterized Execution
|
||||
|
||||
[](https://youtu.be/H0hWjWxB-rg&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=26)
|
||||
|
||||
|
||||
- 2.2.6b - Backfills
|
||||
|
||||
[](https://youtu.be/ZoeC6Ag5gQc&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=27)
|
||||
|
||||
Resources
|
||||
- [Mage Variables Overview](https://docs.mage.ai/development/variables/overview)
|
||||
- [Mage Runtime Variables](https://docs.mage.ai/getting-started/runtime-variable)
|
||||
|
||||
### 2.2.7 - 🤖 Deployment (Optional)
|
||||
|
||||
In this section, we'll cover deploying Mage using Terraform and Google Cloud. This section is optional— it's not *necessary* to learn Mage, but it might be helpful if you're interested in creating a fully deployed project. If you're using Mage in your final project, you'll need to deploy it to the cloud.
|
||||
|
||||
Videos
|
||||
- 2.2.7a - Deployment Prerequisites
|
||||
|
||||
[](https://youtu.be/zAwAX5sxqsg&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=28)
|
||||
|
||||
- 2.2.7b - Google Cloud Permissions
|
||||
|
||||
[](https://youtu.be/O_H7DCmq2rA&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=29)
|
||||
|
||||
- 2.2.7c - Deploying to Google Cloud - Part 1
|
||||
|
||||
[](https://youtu.be/9A872B5hb_0&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=30)
|
||||
|
||||
- 2.2.7d - Deploying to Google Cloud - Part 2
|
||||
|
||||
[](https://youtu.be/0YExsb2HgLI&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=31)
|
||||
|
||||
Resources
|
||||
- [Installing Terraform](https://developer.hashicorp.com/terraform/tutorials/aws-get-started/install-cli)
|
||||
- [Installing `gcloud` CLI](https://cloud.google.com/sdk/docs/install)
|
||||
- [Mage Terraform Templates](https://github.com/mage-ai/mage-ai-terraform-templates)
|
||||
|
||||
Additional Mage Guides
|
||||
- [Terraform](https://docs.mage.ai/production/deploying-to-cloud/using-terraform)
|
||||
- [Deploying to GCP with Terraform](https://docs.mage.ai/production/deploying-to-cloud/gcp/setup)
|
||||
|
||||
### 2.2.8 - 🗒️ Homework
|
||||
|
||||
We've prepared a short exercise to test you on what you've learned this week. You can find the homework [here](../cohorts/2024/02-workflow-orchestration/homework.md). This follows closely from the contents of the course and shouldn't take more than an hour or two to complete. 😄
|
||||
|
||||
### 2.2.9 - 👣 Next Steps
|
||||
|
||||
Congratulations! You've completed Week 2 of the Data Engineering Zoomcamp. We hope you've enjoyed learning about Mage and that you're excited to use it in your final project. If you have any questions, feel free to reach out to us on Slack. Be sure to check out our "Next Steps" video for some inspiration for the rest of your journey 😄.
|
||||
|
||||
Videos
|
||||
- 2.2.9 - Next Steps
|
||||
|
||||
[](https://youtu.be/uUtj7N0TleQ&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=32)
|
||||
|
||||
Resources
|
||||
- [Slides](https://docs.google.com/presentation/d/1yN-e22VNwezmPfKrZkgXQVrX5owDb285I2HxHWgmAEQ/edit#slide=id.g262fb0d2905_0_12)
|
||||
|
||||
### 📑 Additional Resources
|
||||
|
||||
- [Mage Docs](https://docs.mage.ai/)
|
||||
- [Mage Guides](https://docs.mage.ai/guides)
|
||||
- [Mage Slack](https://www.mage.ai/chat)
|
||||
|
||||
|
||||
# Community notes
|
||||
|
||||
Did you take notes? You can share them here:
|
||||
|
||||
## 2024 notes
|
||||
|
||||
* [2024 Videos transcripts week 2](https://drive.google.com/drive/folders/1yxT0uMMYKa6YOxanh91wGqmQUMS7yYW7?usp=sharing) by Maria Fisher
|
||||
* [Notes from Jonah Oliver](https://www.jonahboliver.com/blog/de-zc-w2)
|
||||
* [Notes from Linda](https://github.com/inner-outer-space/de-zoomcamp-2024/blob/main/2-workflow-orchestration/readme.md)
|
||||
* [Notes from Kirill](https://github.com/kirill505/data-engineering-zoomcamp/blob/main/02-workflow-orchestration/README.md)
|
||||
* [Notes from Zharko](https://www.zharconsulting.com/contents/data/data-engineering-bootcamp-2024/week-2-ingesting-data-with-mage/)
|
||||
* Add your notes above this line
|
||||
|
||||
## 2023 notes
|
||||
|
||||
See [here](../cohorts/2023/week_2_workflow_orchestration#community-notes)
|
||||
|
||||
|
||||
## 2022 notes
|
||||
|
||||
See [here](../cohorts/2022/week_2_data_ingestion#community-notes)
|
||||
80
03-data-warehouse/README.md
Normal file
80
03-data-warehouse/README.md
Normal file
@ -0,0 +1,80 @@
|
||||
# Data Warehouse and BigQuery
|
||||
|
||||
- [Slides](https://docs.google.com/presentation/d/1a3ZoBAXFk8-EhUsd7rAZd-5p_HpltkzSeujjRGB2TAI/edit?usp=sharing)
|
||||
- [Big Query basic SQL](big_query.sql)
|
||||
|
||||
# Videos
|
||||
|
||||
## Data Warehouse
|
||||
|
||||
- Data Warehouse and BigQuery
|
||||
|
||||
[](https://youtu.be/jrHljAoD6nM&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=34)
|
||||
|
||||
## :movie_camera: Partitoning and clustering
|
||||
|
||||
- Partioning and Clustering
|
||||
|
||||
[](https://youtu.be/-CqXf7vhhDs&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=35)
|
||||
|
||||
- Partioning vs Clustering
|
||||
|
||||
[](https://youtu.be/-CqXf7vhhDs?si=p1sYQCAs8dAa7jIm&t=193&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=35)
|
||||
|
||||
## :movie_camera: Best practices
|
||||
|
||||
[](https://youtu.be/k81mLJVX08w&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=36)
|
||||
|
||||
## :movie_camera: Internals of BigQuery
|
||||
|
||||
[](https://youtu.be/eduHi1inM4s&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=37)
|
||||
|
||||
## Advanced topics
|
||||
|
||||
### :movie_camera: Machine Learning in Big Query
|
||||
|
||||
[](https://youtu.be/B-WtpB0PuG4&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=34)
|
||||
|
||||
* [SQL for ML in BigQuery](big_query_ml.sql)
|
||||
|
||||
**Important links**
|
||||
|
||||
- [BigQuery ML Tutorials](https://cloud.google.com/bigquery-ml/docs/tutorials)
|
||||
- [BigQuery ML Reference Parameter](https://cloud.google.com/bigquery-ml/docs/analytics-reference-patterns)
|
||||
- [Hyper Parameter tuning](https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-syntax-create-glm)
|
||||
- [Feature preprocessing](https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-syntax-preprocess-overview)
|
||||
|
||||
### :movie_camera: Deploying Machine Learning model from BigQuery
|
||||
|
||||
[](https://youtu.be/BjARzEWaznU&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=39)
|
||||
|
||||
- [Steps to extract and deploy model with docker](extract_model.md)
|
||||
|
||||
|
||||
|
||||
# Homework
|
||||
|
||||
* [2024 Homework](../cohorts/2024/03-data-warehouse/homework.md)
|
||||
|
||||
|
||||
# Community notes
|
||||
|
||||
Did you take notes? You can share them here.
|
||||
|
||||
* [Notes by Alvaro Navas](https://github.com/ziritrion/dataeng-zoomcamp/blob/main/notes/3_data_warehouse.md)
|
||||
* [Isaac Kargar's blog post](https://kargarisaac.github.io/blog/data%20engineering/jupyter/2022/01/30/data-engineering-w3.html)
|
||||
* [Marcos Torregrosa's blog post](https://www.n4gash.com/2023/data-engineering-zoomcamp-semana-3/)
|
||||
* [Notes by Victor Padilha](https://github.com/padilha/de-zoomcamp/tree/master/week3)
|
||||
* [Notes from Xia He-Bleinagel](https://xiahe-bleinagel.com/2023/02/week-3-data-engineering-zoomcamp-notes-data-warehouse-and-bigquery/)
|
||||
* [Bigger picture summary on Data Lakes, Data Warehouses, and tooling](https://medium.com/@verazabeida/zoomcamp-week-4-b8bde661bf98), by Vera
|
||||
* [Notes by froukje](https://github.com/froukje/de-zoomcamp/blob/main/week_3_data_warehouse/notes/notes_week_03.md)
|
||||
* [Notes by Alain Boisvert](https://github.com/boisalai/de-zoomcamp-2023/blob/main/week3.md)
|
||||
* [Notes from Vincenzo Galante](https://binchentso.notion.site/Data-Talks-Club-Data-Engineering-Zoomcamp-8699af8e7ff94ec49e6f9bdec8eb69fd)
|
||||
* [2024 videos transcript week3](https://drive.google.com/drive/folders/1quIiwWO-tJCruqvtlqe_Olw8nvYSmmDJ?usp=sharing) by Maria Fisher
|
||||
* [Notes by Linda](https://github.com/inner-outer-space/de-zoomcamp-2024/blob/main/3a-data-warehouse/readme.md)
|
||||
* [Jonah Oliver's blog post](https://www.jonahboliver.com/blog/de-zc-w3)
|
||||
* [2024 - steps to send data from Mage to GCS + creating external table](https://drive.google.com/file/d/1GIi6xnS4070a8MUlIg-ozITt485_-ePB/view?usp=drive_link) by Maria Fisher
|
||||
* [2024 - mage dataloader script to load the parquet files from a remote URL and push it to Google bucket as parquet file](https://github.com/amohan601/dataengineering-zoomcamp2024/blob/main/week_3_data_warehouse/mage_scripts/green_taxi_2022_v2.py) by Anju Mohan
|
||||
* [2024 - steps to send data from Mage to GCS + creating external table](https://drive.google.com/file/d/1GIi6xnS4070a8MUlIg-ozITt485_-ePB/view?usp=drive_link) by Maria Fisher
|
||||
* [Notes by HongWei](https://github.com/hwchua0209/data-engineering-zoomcamp-submission/blob/main/03-data-warehouse/README.md)
|
||||
* Add your notes here (above this line)
|
||||
140
04-analytics-engineering/README.md
Normal file
140
04-analytics-engineering/README.md
Normal file
@ -0,0 +1,140 @@
|
||||
# Week 4: Analytics Engineering
|
||||
Goal: Transforming the data loaded in DWH into Analytical Views developing a [dbt project](taxi_rides_ny/README.md).
|
||||
|
||||
### Prerequisites
|
||||
By this stage of the course you should have already:
|
||||
|
||||
- A running warehouse (BigQuery or postgres)
|
||||
- A set of running pipelines ingesting the project dataset (week 3 completed)
|
||||
- The following datasets ingested from the course [Datasets list](https://github.com/DataTalksClub/nyc-tlc-data/):
|
||||
* Yellow taxi data - Years 2019 and 2020
|
||||
* Green taxi data - Years 2019 and 2020
|
||||
* fhv data - Year 2019.
|
||||
|
||||
> [!NOTE]
|
||||
> * We have two quick hack to load that data quicker, follow [this video](https://www.youtube.com/watch?v=Mork172sK_c&list=PLaNLNpjZpzwgneiI-Gl8df8GCsPYp_6Bs) for option 1 or check instructions in [week3/extras](../03-data-warehouse/extras) for option 2
|
||||
|
||||
## Setting up your environment
|
||||
|
||||
> [!NOTE]
|
||||
> the *cloud* setup is the preferred option.
|
||||
>
|
||||
> the *local* setup does not require a cloud database.
|
||||
|
||||
| Alternative A | Alternative B |
|
||||
---|---|
|
||||
| Setting up dbt for using BigQuery (cloud) | Setting up dbt for using Postgres locally |
|
||||
|- Open a free developer dbt cloud account following [this link](https://www.getdbt.com/signup/)|- Open a free developer dbt cloud account following [this link](https://www.getdbt.com/signup/)<br><br> |
|
||||
| - [Following these instructions to connect to your BigQuery instance]([https://docs.getdbt.com/docs/dbt-cloud/cloud-configuring-dbt-cloud/cloud-setting-up-bigquery-oauth](https://docs.getdbt.com/guides/bigquery?step=4)) | - follow the [official dbt documentation]([https://docs.getdbt.com/dbt-cli/installation](https://docs.getdbt.com/docs/core/installation-overview)) or <br>- follow the [dbt core with BigQuery on Docker](docker_setup/README.md) guide to setup dbt locally on docker or <br>- use a docker image from oficial [Install with Docker](https://docs.getdbt.com/docs/core/docker-install). |
|
||||
|- More detailed instructions in [dbt_cloud_setup.md](dbt_cloud_setup.md) | - You will need to install the latest version with the BigQuery adapter (dbt-bigquery).|
|
||||
| | - You will need to install the latest version with the postgres adapter (dbt-postgres).|
|
||||
| | After local installation you will have to set up the connection to PG in the `profiles.yml`, you can find the templates [here](https://docs.getdbt.com/docs/core/connect-data-platform/postgres-setup) |
|
||||
|
||||
|
||||
## Content
|
||||
|
||||
### Introduction to analytics engineering
|
||||
|
||||
* What is analytics engineering?
|
||||
* ETL vs ELT
|
||||
* Data modeling concepts (fact and dim tables)
|
||||
|
||||
[](https://youtu.be/uF76d5EmdtU&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=40)
|
||||
|
||||
### What is dbt?
|
||||
|
||||
* Introduction to dbt
|
||||
|
||||
[](https://www.youtube.com/watch?v=gsKuETFJr54&list=PLaNLNpjZpzwgneiI-Gl8df8GCsPYp_6Bs&index=5)
|
||||
|
||||
## Starting a dbt project
|
||||
|
||||
| Alternative A | Alternative B |
|
||||
|-----------------------------|--------------------------------|
|
||||
| Using BigQuery + dbt cloud | Using Postgres + dbt core (locally) |
|
||||
| - Starting a new project with dbt init (dbt cloud and core)<br>- dbt cloud setup<br>- project.yml<br><br> | - Starting a new project with dbt init (dbt cloud and core)<br>- dbt core local setup<br>- profiles.yml<br>- project.yml |
|
||||
| [](https://www.youtube.com/watch?v=J0XCDyKiU64&list=PLaNLNpjZpzwgneiI-Gl8df8GCsPYp_6Bs&index=4) | [](https://youtu.be/1HmL63e-vRs&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=43) |
|
||||
|
||||
### dbt models
|
||||
|
||||
* Anatomy of a dbt model: written code vs compiled Sources
|
||||
* Materialisations: table, view, incremental, ephemeral
|
||||
* Seeds, sources and ref
|
||||
* Jinja and Macros
|
||||
* Packages
|
||||
* Variables
|
||||
|
||||
[](https://www.youtube.com/watch?v=ueVy2N54lyc&list=PLaNLNpjZpzwgneiI-Gl8df8GCsPYp_6Bs&index=3)
|
||||
|
||||
> [!NOTE]
|
||||
> *This video is shown entirely on dbt cloud IDE but the same steps can be followed locally on the IDE of your choice*
|
||||
|
||||
> [!TIP]
|
||||
>* If you recieve an error stating "Permission denied while globbing file pattern." when attempting to run `fact_trips.sql` this video may be helpful in resolving the issue
|
||||
>
|
||||
>[](https://youtu.be/kL3ZVNL9Y4A&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=34)
|
||||
|
||||
### Testing and documenting dbt models
|
||||
* Tests
|
||||
* Documentation
|
||||
|
||||
[](https://www.youtube.com/watch?v=2dNJXHFCHaY&list=PLaNLNpjZpzwgneiI-Gl8df8GCsPYp_6Bs&index=2)
|
||||
|
||||
>[!NOTE]
|
||||
> *This video is shown entirely on dbt cloud IDE but the same steps can be followed locally on the IDE of your choice*
|
||||
|
||||
## Deployment
|
||||
|
||||
| Alternative A | Alternative B |
|
||||
|-----------------------------|--------------------------------|
|
||||
| Using BigQuery + dbt cloud | Using Postgres + dbt core (locally) |
|
||||
| - Deployment: development environment vs production<br>- dbt cloud: scheduler, sources and hosted documentation | - Deployment: development environment vs production<br>- dbt cloud: scheduler, sources and hosted documentation |
|
||||
| [](https://www.youtube.com/watch?v=V2m5C0n8Gro&list=PLaNLNpjZpzwgneiI-Gl8df8GCsPYp_6Bs&index=6) | [](https://youtu.be/Cs9Od1pcrzM&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=47) |
|
||||
|
||||
## Visualising the transformed data
|
||||
|
||||
:movie_camera: Google data studio Video (Now renamed to Looker studio)
|
||||
|
||||
[](https://youtu.be/39nLTs74A3E&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=48)
|
||||
|
||||
:movie_camera: Metabase Video
|
||||
|
||||
[](https://youtu.be/BnLkrA7a6gM&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=49)
|
||||
|
||||
|
||||
## Advanced concepts
|
||||
|
||||
* [Make a model Incremental](https://docs.getdbt.com/docs/building-a-dbt-project/building-models/configuring-incremental-models)
|
||||
* [Use of tags](https://docs.getdbt.com/reference/resource-configs/tags)
|
||||
* [Hooks](https://docs.getdbt.com/docs/building-a-dbt-project/hooks-operations)
|
||||
* [Analysis](https://docs.getdbt.com/docs/building-a-dbt-project/analyses)
|
||||
* [Snapshots](https://docs.getdbt.com/docs/building-a-dbt-project/snapshots)
|
||||
* [Exposure](https://docs.getdbt.com/docs/building-a-dbt-project/exposures)
|
||||
* [Metrics](https://docs.getdbt.com/docs/building-a-dbt-project/metrics)
|
||||
|
||||
|
||||
## Community notes
|
||||
|
||||
Did you take notes? You can share them here.
|
||||
|
||||
* [Notes by Alvaro Navas](https://github.com/ziritrion/dataeng-zoomcamp/blob/main/notes/4_analytics.md)
|
||||
* [Sandy's DE learning blog](https://learningdataengineering540969211.wordpress.com/2022/02/17/week-4-setting-up-dbt-cloud-with-bigquery/)
|
||||
* [Notes by Victor Padilha](https://github.com/padilha/de-zoomcamp/tree/master/week4)
|
||||
* [Marcos Torregrosa's blog (spanish)](https://www.n4gash.com/2023/data-engineering-zoomcamp-semana-4/)
|
||||
* [Notes by froukje](https://github.com/froukje/de-zoomcamp/blob/main/week_4_analytics_engineering/notes/notes_week_04.md)
|
||||
* [Notes by Alain Boisvert](https://github.com/boisalai/de-zoomcamp-2023/blob/main/week4.md)
|
||||
* [Setting up Prefect with dbt by Vera](https://medium.com/@verazabeida/zoomcamp-week-5-5b6a9d53a3a0)
|
||||
* [Blog by Xia He-Bleinagel](https://xiahe-bleinagel.com/2023/02/week-4-data-engineering-zoomcamp-notes-analytics-engineering-and-dbt/)
|
||||
* [Setting up DBT with BigQuery by Tofag](https://medium.com/@fagbuyit/setting-up-your-dbt-cloud-dej-9-d18e5b7c96ba)
|
||||
* [Blog post by Dewi Oktaviani](https://medium.com/@oktavianidewi/de-zoomcamp-2023-learning-week-4-analytics-engineering-with-dbt-53f781803d3e)
|
||||
* [Notes from Vincenzo Galante](https://binchentso.notion.site/Data-Talks-Club-Data-Engineering-Zoomcamp-8699af8e7ff94ec49e6f9bdec8eb69fd)
|
||||
* [Notes from Balaji](https://github.com/Balajirvp/DE-Zoomcamp/blob/main/Week%204/Data%20Engineering%20Zoomcamp%20Week%204.ipynb)
|
||||
* [Notes by Linda](https://github.com/inner-outer-space/de-zoomcamp-2024/blob/main/4-analytics-engineering/readme.md)
|
||||
* [2024 - Videos transcript week4](https://drive.google.com/drive/folders/1V2sHWOotPEMQTdMT4IMki1fbMPTn3jOP?usp=drive)
|
||||
* [Blog Post](https://www.jonahboliver.com/blog/de-zc-w4) by Jonah Oliver
|
||||
* Add your notes here (above this line)
|
||||
|
||||
## Useful links
|
||||
- [Slides used in the videos](https://docs.google.com/presentation/d/1xSll_jv0T8JF4rYZvLHfkJXYqUjPtThA/edit?usp=sharing&ouid=114544032874539580154&rtpof=true&sd=true)
|
||||
- [Visualizing data with Metabase course](https://www.metabase.com/learn/visualization/)
|
||||
- [dbt free courses](https://courses.getdbt.com/collections)
|
||||
5
04-analytics-engineering/taxi_rides_ny/.gitignore
vendored
Normal file
5
04-analytics-engineering/taxi_rides_ny/.gitignore
vendored
Normal file
@ -0,0 +1,5 @@
|
||||
# you shouldn't commit these into source control
|
||||
# these are the default directory names, adjust/add to fit your needs
|
||||
target/
|
||||
dbt_packages/
|
||||
logs/
|
||||
@ -35,4 +35,4 @@ _Alternative: use `$ dbt build` to execute with one command the 3 steps above to
|
||||
- Check out [Discourse](https://discourse.getdbt.com/) for commonly asked questions and answers
|
||||
- Join the [chat](http://slack.getdbt.com/) on Slack for live discussions and support
|
||||
- Find [dbt events](https://events.getdbt.com) near you
|
||||
- Check out [the blog](https://blog.getdbt.com/) for the latest news on dbt's development and best practices
|
||||
- Check out [the blog](https://blog.getdbt.com/) for the latest news on dbt's development and best practices
|
||||
@ -0,0 +1,49 @@
|
||||
-- MAKE SURE YOU REPLACE taxi-rides-ny-339813-412521 WITH THE NAME OF YOUR DATASET!
|
||||
-- When you run the query, only run 5 of the ALTER TABLE statements at one time (by highlighting only 5).
|
||||
-- Otherwise BigQuery will say too many alterations to the table are being made.
|
||||
|
||||
CREATE TABLE `taxi-rides-ny-339813-412521.trips_data_all.green_tripdata` as
|
||||
SELECT * FROM `bigquery-public-data.new_york_taxi_trips.tlc_green_trips_2019`;
|
||||
|
||||
|
||||
CREATE TABLE `taxi-rides-ny-339813-412521.trips_data_all.yellow_tripdata` as
|
||||
SELECT * FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2019`;
|
||||
|
||||
insert into `taxi-rides-ny-339813-412521.trips_data_all.green_tripdata`
|
||||
SELECT * FROM `bigquery-public-data.new_york_taxi_trips.tlc_green_trips_2020` ;
|
||||
|
||||
|
||||
insert into `taxi-rides-ny-339813-412521.trips_data_all.yellow_tripdata`
|
||||
SELECT * FROM `bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2020`;
|
||||
|
||||
-- Fixes yellow table schema
|
||||
ALTER TABLE `taxi-rides-ny-339813-412521.trips_data_all.yellow_tripdata`
|
||||
RENAME COLUMN vendor_id TO VendorID;
|
||||
ALTER TABLE `taxi-rides-ny-339813-412521.trips_data_all.yellow_tripdata`
|
||||
RENAME COLUMN pickup_datetime TO tpep_pickup_datetime;
|
||||
ALTER TABLE `taxi-rides-ny-339813-412521.trips_data_all.yellow_tripdata`
|
||||
RENAME COLUMN dropoff_datetime TO tpep_dropoff_datetime;
|
||||
ALTER TABLE `taxi-rides-ny-339813-412521.trips_data_all.yellow_tripdata`
|
||||
RENAME COLUMN rate_code TO RatecodeID;
|
||||
ALTER TABLE `taxi-rides-ny-339813-412521.trips_data_all.yellow_tripdata`
|
||||
RENAME COLUMN imp_surcharge TO improvement_surcharge;
|
||||
ALTER TABLE `taxi-rides-ny-339813-412521.trips_data_all.yellow_tripdata`
|
||||
RENAME COLUMN pickup_location_id TO PULocationID;
|
||||
ALTER TABLE `taxi-rides-ny-339813-412521.trips_data_all.yellow_tripdata`
|
||||
RENAME COLUMN dropoff_location_id TO DOLocationID;
|
||||
|
||||
-- Fixes green table schema
|
||||
ALTER TABLE `taxi-rides-ny-339813-412521.trips_data_all.green_tripdata`
|
||||
RENAME COLUMN vendor_id TO VendorID;
|
||||
ALTER TABLE `taxi-rides-ny-339813-412521.trips_data_all.green_tripdata`
|
||||
RENAME COLUMN pickup_datetime TO lpep_pickup_datetime;
|
||||
ALTER TABLE `taxi-rides-ny-339813-412521.trips_data_all.green_tripdata`
|
||||
RENAME COLUMN dropoff_datetime TO lpep_dropoff_datetime;
|
||||
ALTER TABLE `taxi-rides-ny-339813-412521.trips_data_all.green_tripdata`
|
||||
RENAME COLUMN rate_code TO RatecodeID;
|
||||
ALTER TABLE `taxi-rides-ny-339813-412521.trips_data_all.green_tripdata`
|
||||
RENAME COLUMN imp_surcharge TO improvement_surcharge;
|
||||
ALTER TABLE `taxi-rides-ny-339813-412521.trips_data_all.green_tripdata`
|
||||
RENAME COLUMN pickup_location_id TO PULocationID;
|
||||
ALTER TABLE `taxi-rides-ny-339813-412521.trips_data_all.green_tripdata`
|
||||
RENAME COLUMN dropoff_location_id TO DOLocationID;
|
||||
@ -7,13 +7,13 @@ version: '1.0.0'
|
||||
config-version: 2
|
||||
|
||||
# This setting configures which "profile" dbt uses for this project.
|
||||
profile: 'pg-dbt-workshop'
|
||||
profile: 'default'
|
||||
|
||||
# These configurations specify where dbt should look for different types of files.
|
||||
# The `source-paths` config, for example, states that models in this project can be
|
||||
# The `model-paths` config, for example, states that models in this project can be
|
||||
# found in the "models/" directory. You probably won't need to change these!
|
||||
model-paths: ["models"]
|
||||
analysis-paths: ["analysis"]
|
||||
analysis-paths: ["analyses"]
|
||||
test-paths: ["tests"]
|
||||
seed-paths: ["seeds"]
|
||||
macro-paths: ["macros"]
|
||||
@ -21,17 +21,20 @@ snapshot-paths: ["snapshots"]
|
||||
|
||||
target-path: "target" # directory which will store compiled SQL files
|
||||
clean-targets: # directories to be removed by `dbt clean`
|
||||
- "target"
|
||||
- "dbt_packages"
|
||||
- "dbt_modules"
|
||||
- "target"
|
||||
- "dbt_packages"
|
||||
|
||||
|
||||
# Configuring models
|
||||
# Full documentation: https://docs.getdbt.com/docs/configuring-models
|
||||
|
||||
# In this example config, we tell dbt to build all models in the example/ directory
|
||||
# as tables. These settings can be overridden in the individual model files
|
||||
# In dbt, the default materialization for a model is a view. This means, when you run
|
||||
# dbt run or dbt build, all of your models will be built as a view in your data platform.
|
||||
# The configuration below will override this setting for models in the example folder to
|
||||
# instead be materialized as tables. Any models you add to the root of the models folder will
|
||||
# continue to be built as views. These settings can be overridden in the individual model files
|
||||
# using the `{{ config(...) }}` macro.
|
||||
|
||||
models:
|
||||
taxi_rides_ny:
|
||||
# Applies to all files under models/.../
|
||||
@ -46,4 +49,4 @@ seeds:
|
||||
taxi_rides_ny:
|
||||
taxi_zone_lookup:
|
||||
+column_types:
|
||||
locationid: numeric
|
||||
locationid: numeric
|
||||
@ -1,18 +1,17 @@
|
||||
{#
|
||||
{#
|
||||
This macro returns the description of the payment_type
|
||||
#}
|
||||
|
||||
{% macro get_payment_type_description(payment_type) -%}
|
||||
|
||||
case {{ payment_type }}
|
||||
case {{ dbt.safe_cast("payment_type", api.Column.translate_type("integer")) }}
|
||||
when 1 then 'Credit card'
|
||||
when 2 then 'Cash'
|
||||
when 3 then 'No charge'
|
||||
when 4 then 'Dispute'
|
||||
when 5 then 'Unknown'
|
||||
when 6 then 'Voided trip'
|
||||
else 'EMPTY'
|
||||
end
|
||||
|
||||
{%- endmacro %}
|
||||
|
||||
|
||||
{%- endmacro %}
|
||||
@ -1,9 +1,8 @@
|
||||
{{ config(materialized='table') }}
|
||||
|
||||
|
||||
select
|
||||
locationid,
|
||||
borough,
|
||||
zone,
|
||||
replace(service_zone,'Boro','Green') as service_zone
|
||||
replace(service_zone,'Boro','Green') as service_zone
|
||||
from {{ ref('taxi_zone_lookup') }}
|
||||
@ -6,8 +6,7 @@ with trips_data as (
|
||||
select
|
||||
-- Reveneue grouping
|
||||
pickup_zone as revenue_zone,
|
||||
date_trunc('month', pickup_datetime) as revenue_month,
|
||||
--Note: For BQ use instead: date_trunc(pickup_datetime, month) as revenue_month,
|
||||
{{ dbt.date_trunc("month", "pickup_datetime") }} as revenue_month,
|
||||
|
||||
service_type,
|
||||
|
||||
@ -20,12 +19,11 @@ with trips_data as (
|
||||
sum(ehail_fee) as revenue_monthly_ehail_fee,
|
||||
sum(improvement_surcharge) as revenue_monthly_improvement_surcharge,
|
||||
sum(total_amount) as revenue_monthly_total_amount,
|
||||
sum(congestion_surcharge) as revenue_monthly_congestion_surcharge,
|
||||
|
||||
-- Additional calculations
|
||||
count(tripid) as total_monthly_trips,
|
||||
avg(passenger_count) as avg_montly_passenger_count,
|
||||
avg(trip_distance) as avg_montly_trip_distance
|
||||
avg(passenger_count) as avg_monthly_passenger_count,
|
||||
avg(trip_distance) as avg_monthly_trip_distance
|
||||
|
||||
from trips_data
|
||||
group by 1,2,3
|
||||
group by 1,2,3
|
||||
@ -1,29 +1,29 @@
|
||||
{{ config(materialized='table') }}
|
||||
{{
|
||||
config(
|
||||
materialized='table'
|
||||
)
|
||||
}}
|
||||
|
||||
with green_data as (
|
||||
with green_tripdata as (
|
||||
select *,
|
||||
'Green' as service_type
|
||||
'Green' as service_type
|
||||
from {{ ref('stg_green_tripdata') }}
|
||||
),
|
||||
|
||||
yellow_data as (
|
||||
yellow_tripdata as (
|
||||
select *,
|
||||
'Yellow' as service_type
|
||||
from {{ ref('stg_yellow_tripdata') }}
|
||||
),
|
||||
|
||||
trips_unioned as (
|
||||
select * from green_data
|
||||
union all
|
||||
select * from yellow_data
|
||||
select * from green_tripdata
|
||||
union all
|
||||
select * from yellow_tripdata
|
||||
),
|
||||
|
||||
dim_zones as (
|
||||
select * from {{ ref('dim_zones') }}
|
||||
where borough != 'Unknown'
|
||||
)
|
||||
select
|
||||
trips_unioned.tripid,
|
||||
select trips_unioned.tripid,
|
||||
trips_unioned.vendorid,
|
||||
trips_unioned.service_type,
|
||||
trips_unioned.ratecodeid,
|
||||
@ -48,10 +48,9 @@ select
|
||||
trips_unioned.improvement_surcharge,
|
||||
trips_unioned.total_amount,
|
||||
trips_unioned.payment_type,
|
||||
trips_unioned.payment_type_description,
|
||||
trips_unioned.congestion_surcharge
|
||||
trips_unioned.payment_type_description
|
||||
from trips_unioned
|
||||
inner join dim_zones as pickup_zone
|
||||
on trips_unioned.pickup_locationid = pickup_zone.locationid
|
||||
inner join dim_zones as dropoff_zone
|
||||
on trips_unioned.dropoff_locationid = dropoff_zone.locationid
|
||||
on trips_unioned.dropoff_locationid = dropoff_zone.locationid
|
||||
129
04-analytics-engineering/taxi_rides_ny/models/core/schema.yml
Normal file
129
04-analytics-engineering/taxi_rides_ny/models/core/schema.yml
Normal file
@ -0,0 +1,129 @@
|
||||
version: 2
|
||||
|
||||
models:
|
||||
- name: dim_zones
|
||||
description: >
|
||||
List of unique zones idefied by locationid.
|
||||
Includes the service zone they correspond to (Green or yellow).
|
||||
|
||||
- name: dm_monthly_zone_revenue
|
||||
description: >
|
||||
Aggregated table of all taxi trips corresponding to both service zones (Green and yellow) per pickup zone, month and service.
|
||||
The table contains monthly sums of the fare elements used to calculate the monthly revenue.
|
||||
The table contains also monthly indicators like number of trips, and average trip distance.
|
||||
columns:
|
||||
- name: revenue_monthly_total_amount
|
||||
description: Monthly sum of the the total_amount of the fare charged for the trip per pickup zone, month and service.
|
||||
tests:
|
||||
- not_null:
|
||||
severity: error
|
||||
|
||||
- name: fact_trips
|
||||
description: >
|
||||
Taxi trips corresponding to both service zones (Green and yellow).
|
||||
The table contains records where both pickup and dropoff locations are valid and known zones.
|
||||
Each record corresponds to a trip uniquely identified by tripid.
|
||||
columns:
|
||||
- name: tripid
|
||||
data_type: string
|
||||
description: "unique identifier conformed by the combination of vendorid and pickyp time"
|
||||
|
||||
- name: vendorid
|
||||
data_type: int64
|
||||
description: ""
|
||||
|
||||
- name: service_type
|
||||
data_type: string
|
||||
description: ""
|
||||
|
||||
- name: ratecodeid
|
||||
data_type: int64
|
||||
description: ""
|
||||
|
||||
- name: pickup_locationid
|
||||
data_type: int64
|
||||
description: ""
|
||||
|
||||
- name: pickup_borough
|
||||
data_type: string
|
||||
description: ""
|
||||
|
||||
- name: pickup_zone
|
||||
data_type: string
|
||||
description: ""
|
||||
|
||||
- name: dropoff_locationid
|
||||
data_type: int64
|
||||
description: ""
|
||||
|
||||
- name: dropoff_borough
|
||||
data_type: string
|
||||
description: ""
|
||||
|
||||
- name: dropoff_zone
|
||||
data_type: string
|
||||
description: ""
|
||||
|
||||
- name: pickup_datetime
|
||||
data_type: timestamp
|
||||
description: ""
|
||||
|
||||
- name: dropoff_datetime
|
||||
data_type: timestamp
|
||||
description: ""
|
||||
|
||||
- name: store_and_fwd_flag
|
||||
data_type: string
|
||||
description: ""
|
||||
|
||||
- name: passenger_count
|
||||
data_type: int64
|
||||
description: ""
|
||||
|
||||
- name: trip_distance
|
||||
data_type: numeric
|
||||
description: ""
|
||||
|
||||
- name: trip_type
|
||||
data_type: int64
|
||||
description: ""
|
||||
|
||||
- name: fare_amount
|
||||
data_type: numeric
|
||||
description: ""
|
||||
|
||||
- name: extra
|
||||
data_type: numeric
|
||||
description: ""
|
||||
|
||||
- name: mta_tax
|
||||
data_type: numeric
|
||||
description: ""
|
||||
|
||||
- name: tip_amount
|
||||
data_type: numeric
|
||||
description: ""
|
||||
|
||||
- name: tolls_amount
|
||||
data_type: numeric
|
||||
description: ""
|
||||
|
||||
- name: ehail_fee
|
||||
data_type: numeric
|
||||
description: ""
|
||||
|
||||
- name: improvement_surcharge
|
||||
data_type: numeric
|
||||
description: ""
|
||||
|
||||
- name: total_amount
|
||||
data_type: numeric
|
||||
description: ""
|
||||
|
||||
- name: payment_type
|
||||
data_type: int64
|
||||
description: ""
|
||||
|
||||
- name: payment_type_description
|
||||
data_type: string
|
||||
description: ""
|
||||
@ -1,20 +1,16 @@
|
||||
|
||||
version: 2
|
||||
|
||||
sources:
|
||||
- name: staging
|
||||
#For bigquery:
|
||||
#database: taxi-rides-ny-339813
|
||||
|
||||
# For postgres:
|
||||
database: production
|
||||
|
||||
schema: trips_data_all
|
||||
- name: staging
|
||||
database: taxi-rides-ny-339813-412521
|
||||
# For postgres:
|
||||
#database: production
|
||||
schema: trips_data_all
|
||||
|
||||
# loaded_at_field: record_loaded_at
|
||||
tables:
|
||||
- name: green_tripdata
|
||||
- name: yellow_tripdata
|
||||
tables:
|
||||
- name: green_tripdata
|
||||
- name: yellow_tripdata
|
||||
# freshness:
|
||||
# error_after: {count: 6, period: hour}
|
||||
|
||||
@ -75,7 +71,7 @@ models:
|
||||
memory before sending to the vendor, aka “store and forward,”
|
||||
because the vehicle did not have a connection to the server.
|
||||
Y= store and forward trip
|
||||
N= not a store and forward trip
|
||||
N = not a store and forward trip
|
||||
- name: Dropoff_longitude
|
||||
description: Longitude where the meter was disengaged.
|
||||
- name: Dropoff_latitude
|
||||
@ -200,4 +196,4 @@ models:
|
||||
- name: Tolls_amount
|
||||
description: Total amount of all tolls paid in trip.
|
||||
- name: Total_amount
|
||||
description: The total amount charged to passengers. Does not include cash tips.
|
||||
description: The total amount charged to passengers. Does not include cash tips.
|
||||
@ -0,0 +1,52 @@
|
||||
{{
|
||||
config(
|
||||
materialized='view'
|
||||
)
|
||||
}}
|
||||
|
||||
with tripdata as
|
||||
(
|
||||
select *,
|
||||
row_number() over(partition by vendorid, lpep_pickup_datetime) as rn
|
||||
from {{ source('staging','green_tripdata') }}
|
||||
where vendorid is not null
|
||||
)
|
||||
select
|
||||
-- identifiers
|
||||
{{ dbt_utils.generate_surrogate_key(['vendorid', 'lpep_pickup_datetime']) }} as tripid,
|
||||
{{ dbt.safe_cast("vendorid", api.Column.translate_type("integer")) }} as vendorid,
|
||||
{{ dbt.safe_cast("ratecodeid", api.Column.translate_type("integer")) }} as ratecodeid,
|
||||
{{ dbt.safe_cast("pulocationid", api.Column.translate_type("integer")) }} as pickup_locationid,
|
||||
{{ dbt.safe_cast("dolocationid", api.Column.translate_type("integer")) }} as dropoff_locationid,
|
||||
|
||||
-- timestamps
|
||||
cast(lpep_pickup_datetime as timestamp) as pickup_datetime,
|
||||
cast(lpep_dropoff_datetime as timestamp) as dropoff_datetime,
|
||||
|
||||
-- trip info
|
||||
store_and_fwd_flag,
|
||||
{{ dbt.safe_cast("passenger_count", api.Column.translate_type("integer")) }} as passenger_count,
|
||||
cast(trip_distance as numeric) as trip_distance,
|
||||
{{ dbt.safe_cast("trip_type", api.Column.translate_type("integer")) }} as trip_type,
|
||||
|
||||
-- payment info
|
||||
cast(fare_amount as numeric) as fare_amount,
|
||||
cast(extra as numeric) as extra,
|
||||
cast(mta_tax as numeric) as mta_tax,
|
||||
cast(tip_amount as numeric) as tip_amount,
|
||||
cast(tolls_amount as numeric) as tolls_amount,
|
||||
cast(ehail_fee as numeric) as ehail_fee,
|
||||
cast(improvement_surcharge as numeric) as improvement_surcharge,
|
||||
cast(total_amount as numeric) as total_amount,
|
||||
coalesce({{ dbt.safe_cast("payment_type", api.Column.translate_type("integer")) }},0) as payment_type,
|
||||
{{ get_payment_type_description("payment_type") }} as payment_type_description
|
||||
from tripdata
|
||||
where rn = 1
|
||||
|
||||
|
||||
-- dbt build --select <model_name> --vars '{'is_test_run': 'false'}'
|
||||
{% if var('is_test_run', default=true) %}
|
||||
|
||||
limit 100
|
||||
|
||||
{% endif %}
|
||||
@ -9,19 +9,19 @@ with tripdata as
|
||||
)
|
||||
select
|
||||
-- identifiers
|
||||
{{ dbt_utils.surrogate_key(['vendorid', 'tpep_pickup_datetime']) }} as tripid,
|
||||
cast(vendorid as integer) as vendorid,
|
||||
cast(ratecodeid as integer) as ratecodeid,
|
||||
cast(pulocationid as integer) as pickup_locationid,
|
||||
cast(dolocationid as integer) as dropoff_locationid,
|
||||
|
||||
{{ dbt_utils.generate_surrogate_key(['vendorid', 'tpep_pickup_datetime']) }} as tripid,
|
||||
{{ dbt.safe_cast("vendorid", api.Column.translate_type("integer")) }} as vendorid,
|
||||
{{ dbt.safe_cast("ratecodeid", api.Column.translate_type("integer")) }} as ratecodeid,
|
||||
{{ dbt.safe_cast("pulocationid", api.Column.translate_type("integer")) }} as pickup_locationid,
|
||||
{{ dbt.safe_cast("dolocationid", api.Column.translate_type("integer")) }} as dropoff_locationid,
|
||||
|
||||
-- timestamps
|
||||
cast(tpep_pickup_datetime as timestamp) as pickup_datetime,
|
||||
cast(tpep_dropoff_datetime as timestamp) as dropoff_datetime,
|
||||
|
||||
-- trip info
|
||||
store_and_fwd_flag,
|
||||
cast(passenger_count as integer) as passenger_count,
|
||||
{{ dbt.safe_cast("passenger_count", api.Column.translate_type("integer")) }} as passenger_count,
|
||||
cast(trip_distance as numeric) as trip_distance,
|
||||
-- yellow cabs are always street-hail
|
||||
1 as trip_type,
|
||||
@ -35,16 +35,14 @@ select
|
||||
cast(0 as numeric) as ehail_fee,
|
||||
cast(improvement_surcharge as numeric) as improvement_surcharge,
|
||||
cast(total_amount as numeric) as total_amount,
|
||||
cast(payment_type as integer) as payment_type,
|
||||
{{ get_payment_type_description('payment_type') }} as payment_type_description,
|
||||
cast(congestion_surcharge as numeric) as congestion_surcharge
|
||||
coalesce({{ dbt.safe_cast("payment_type", api.Column.translate_type("integer")) }},0) as payment_type,
|
||||
{{ get_payment_type_description('payment_type') }} as payment_type_description
|
||||
from tripdata
|
||||
where rn = 1
|
||||
|
||||
-- dbt build --m <model.sql> --var 'is_test_run: false'
|
||||
-- dbt build --select <model.sql> --vars '{'is_test_run: false}'
|
||||
{% if var('is_test_run', default=true) %}
|
||||
|
||||
limit 100
|
||||
|
||||
{% endif %}
|
||||
|
||||
{% endif %}
|
||||
6
04-analytics-engineering/taxi_rides_ny/package-lock.yml
Normal file
6
04-analytics-engineering/taxi_rides_ny/package-lock.yml
Normal file
@ -0,0 +1,6 @@
|
||||
packages:
|
||||
- package: dbt-labs/dbt_utils
|
||||
version: 1.1.1
|
||||
- package: dbt-labs/codegen
|
||||
version: 0.12.1
|
||||
sha1_hash: d974113b0f072cce35300077208f38581075ab40
|
||||
5
04-analytics-engineering/taxi_rides_ny/packages.yml
Normal file
5
04-analytics-engineering/taxi_rides_ny/packages.yml
Normal file
@ -0,0 +1,5 @@
|
||||
packages:
|
||||
- package: dbt-labs/dbt_utils
|
||||
version: 1.1.1
|
||||
- package: dbt-labs/codegen
|
||||
version: 0.12.1
|
||||
@ -6,5 +6,4 @@ seeds:
|
||||
Taxi Zones roughly based on NYC Department of City Planning's Neighborhood
|
||||
Tabulation Areas (NTAs) and are meant to approximate neighborhoods, so you can see which
|
||||
neighborhood a passenger was picked up in, and which neighborhood they were dropped off in.
|
||||
Includes associated service_zone (EWR, Boro Zone, Yellow Zone)
|
||||
|
||||
Includes associated service_zone (EWR, Boro Zone, Yellow Zone)
|
||||
@ -1,266 +1,266 @@
|
||||
"locationid","borough","zone","service_zone"
|
||||
1,"EWR","Newark Airport","EWR"
|
||||
2,"Queens","Jamaica Bay","Boro Zone"
|
||||
3,"Bronx","Allerton/Pelham Gardens","Boro Zone"
|
||||
4,"Manhattan","Alphabet City","Yellow Zone"
|
||||
5,"Staten Island","Arden Heights","Boro Zone"
|
||||
6,"Staten Island","Arrochar/Fort Wadsworth","Boro Zone"
|
||||
7,"Queens","Astoria","Boro Zone"
|
||||
8,"Queens","Astoria Park","Boro Zone"
|
||||
9,"Queens","Auburndale","Boro Zone"
|
||||
10,"Queens","Baisley Park","Boro Zone"
|
||||
11,"Brooklyn","Bath Beach","Boro Zone"
|
||||
12,"Manhattan","Battery Park","Yellow Zone"
|
||||
13,"Manhattan","Battery Park City","Yellow Zone"
|
||||
14,"Brooklyn","Bay Ridge","Boro Zone"
|
||||
15,"Queens","Bay Terrace/Fort Totten","Boro Zone"
|
||||
16,"Queens","Bayside","Boro Zone"
|
||||
17,"Brooklyn","Bedford","Boro Zone"
|
||||
18,"Bronx","Bedford Park","Boro Zone"
|
||||
19,"Queens","Bellerose","Boro Zone"
|
||||
20,"Bronx","Belmont","Boro Zone"
|
||||
21,"Brooklyn","Bensonhurst East","Boro Zone"
|
||||
22,"Brooklyn","Bensonhurst West","Boro Zone"
|
||||
23,"Staten Island","Bloomfield/Emerson Hill","Boro Zone"
|
||||
24,"Manhattan","Bloomingdale","Yellow Zone"
|
||||
25,"Brooklyn","Boerum Hill","Boro Zone"
|
||||
26,"Brooklyn","Borough Park","Boro Zone"
|
||||
27,"Queens","Breezy Point/Fort Tilden/Riis Beach","Boro Zone"
|
||||
28,"Queens","Briarwood/Jamaica Hills","Boro Zone"
|
||||
29,"Brooklyn","Brighton Beach","Boro Zone"
|
||||
30,"Queens","Broad Channel","Boro Zone"
|
||||
31,"Bronx","Bronx Park","Boro Zone"
|
||||
32,"Bronx","Bronxdale","Boro Zone"
|
||||
33,"Brooklyn","Brooklyn Heights","Boro Zone"
|
||||
34,"Brooklyn","Brooklyn Navy Yard","Boro Zone"
|
||||
35,"Brooklyn","Brownsville","Boro Zone"
|
||||
36,"Brooklyn","Bushwick North","Boro Zone"
|
||||
37,"Brooklyn","Bushwick South","Boro Zone"
|
||||
38,"Queens","Cambria Heights","Boro Zone"
|
||||
39,"Brooklyn","Canarsie","Boro Zone"
|
||||
40,"Brooklyn","Carroll Gardens","Boro Zone"
|
||||
41,"Manhattan","Central Harlem","Boro Zone"
|
||||
42,"Manhattan","Central Harlem North","Boro Zone"
|
||||
43,"Manhattan","Central Park","Yellow Zone"
|
||||
44,"Staten Island","Charleston/Tottenville","Boro Zone"
|
||||
45,"Manhattan","Chinatown","Yellow Zone"
|
||||
46,"Bronx","City Island","Boro Zone"
|
||||
47,"Bronx","Claremont/Bathgate","Boro Zone"
|
||||
48,"Manhattan","Clinton East","Yellow Zone"
|
||||
49,"Brooklyn","Clinton Hill","Boro Zone"
|
||||
50,"Manhattan","Clinton West","Yellow Zone"
|
||||
51,"Bronx","Co-Op City","Boro Zone"
|
||||
52,"Brooklyn","Cobble Hill","Boro Zone"
|
||||
53,"Queens","College Point","Boro Zone"
|
||||
54,"Brooklyn","Columbia Street","Boro Zone"
|
||||
55,"Brooklyn","Coney Island","Boro Zone"
|
||||
56,"Queens","Corona","Boro Zone"
|
||||
57,"Queens","Corona","Boro Zone"
|
||||
58,"Bronx","Country Club","Boro Zone"
|
||||
59,"Bronx","Crotona Park","Boro Zone"
|
||||
60,"Bronx","Crotona Park East","Boro Zone"
|
||||
61,"Brooklyn","Crown Heights North","Boro Zone"
|
||||
62,"Brooklyn","Crown Heights South","Boro Zone"
|
||||
63,"Brooklyn","Cypress Hills","Boro Zone"
|
||||
64,"Queens","Douglaston","Boro Zone"
|
||||
65,"Brooklyn","Downtown Brooklyn/MetroTech","Boro Zone"
|
||||
66,"Brooklyn","DUMBO/Vinegar Hill","Boro Zone"
|
||||
67,"Brooklyn","Dyker Heights","Boro Zone"
|
||||
68,"Manhattan","East Chelsea","Yellow Zone"
|
||||
69,"Bronx","East Concourse/Concourse Village","Boro Zone"
|
||||
70,"Queens","East Elmhurst","Boro Zone"
|
||||
71,"Brooklyn","East Flatbush/Farragut","Boro Zone"
|
||||
72,"Brooklyn","East Flatbush/Remsen Village","Boro Zone"
|
||||
73,"Queens","East Flushing","Boro Zone"
|
||||
74,"Manhattan","East Harlem North","Boro Zone"
|
||||
75,"Manhattan","East Harlem South","Boro Zone"
|
||||
76,"Brooklyn","East New York","Boro Zone"
|
||||
77,"Brooklyn","East New York/Pennsylvania Avenue","Boro Zone"
|
||||
78,"Bronx","East Tremont","Boro Zone"
|
||||
79,"Manhattan","East Village","Yellow Zone"
|
||||
80,"Brooklyn","East Williamsburg","Boro Zone"
|
||||
81,"Bronx","Eastchester","Boro Zone"
|
||||
82,"Queens","Elmhurst","Boro Zone"
|
||||
83,"Queens","Elmhurst/Maspeth","Boro Zone"
|
||||
84,"Staten Island","Eltingville/Annadale/Prince's Bay","Boro Zone"
|
||||
85,"Brooklyn","Erasmus","Boro Zone"
|
||||
86,"Queens","Far Rockaway","Boro Zone"
|
||||
87,"Manhattan","Financial District North","Yellow Zone"
|
||||
88,"Manhattan","Financial District South","Yellow Zone"
|
||||
89,"Brooklyn","Flatbush/Ditmas Park","Boro Zone"
|
||||
90,"Manhattan","Flatiron","Yellow Zone"
|
||||
91,"Brooklyn","Flatlands","Boro Zone"
|
||||
92,"Queens","Flushing","Boro Zone"
|
||||
93,"Queens","Flushing Meadows-Corona Park","Boro Zone"
|
||||
94,"Bronx","Fordham South","Boro Zone"
|
||||
95,"Queens","Forest Hills","Boro Zone"
|
||||
96,"Queens","Forest Park/Highland Park","Boro Zone"
|
||||
97,"Brooklyn","Fort Greene","Boro Zone"
|
||||
98,"Queens","Fresh Meadows","Boro Zone"
|
||||
99,"Staten Island","Freshkills Park","Boro Zone"
|
||||
100,"Manhattan","Garment District","Yellow Zone"
|
||||
101,"Queens","Glen Oaks","Boro Zone"
|
||||
102,"Queens","Glendale","Boro Zone"
|
||||
103,"Manhattan","Governor's Island/Ellis Island/Liberty Island","Yellow Zone"
|
||||
104,"Manhattan","Governor's Island/Ellis Island/Liberty Island","Yellow Zone"
|
||||
105,"Manhattan","Governor's Island/Ellis Island/Liberty Island","Yellow Zone"
|
||||
106,"Brooklyn","Gowanus","Boro Zone"
|
||||
107,"Manhattan","Gramercy","Yellow Zone"
|
||||
108,"Brooklyn","Gravesend","Boro Zone"
|
||||
109,"Staten Island","Great Kills","Boro Zone"
|
||||
110,"Staten Island","Great Kills Park","Boro Zone"
|
||||
111,"Brooklyn","Green-Wood Cemetery","Boro Zone"
|
||||
112,"Brooklyn","Greenpoint","Boro Zone"
|
||||
113,"Manhattan","Greenwich Village North","Yellow Zone"
|
||||
114,"Manhattan","Greenwich Village South","Yellow Zone"
|
||||
115,"Staten Island","Grymes Hill/Clifton","Boro Zone"
|
||||
116,"Manhattan","Hamilton Heights","Boro Zone"
|
||||
117,"Queens","Hammels/Arverne","Boro Zone"
|
||||
118,"Staten Island","Heartland Village/Todt Hill","Boro Zone"
|
||||
119,"Bronx","Highbridge","Boro Zone"
|
||||
120,"Manhattan","Highbridge Park","Boro Zone"
|
||||
121,"Queens","Hillcrest/Pomonok","Boro Zone"
|
||||
122,"Queens","Hollis","Boro Zone"
|
||||
123,"Brooklyn","Homecrest","Boro Zone"
|
||||
124,"Queens","Howard Beach","Boro Zone"
|
||||
125,"Manhattan","Hudson Sq","Yellow Zone"
|
||||
126,"Bronx","Hunts Point","Boro Zone"
|
||||
127,"Manhattan","Inwood","Boro Zone"
|
||||
128,"Manhattan","Inwood Hill Park","Boro Zone"
|
||||
129,"Queens","Jackson Heights","Boro Zone"
|
||||
130,"Queens","Jamaica","Boro Zone"
|
||||
131,"Queens","Jamaica Estates","Boro Zone"
|
||||
132,"Queens","JFK Airport","Airports"
|
||||
133,"Brooklyn","Kensington","Boro Zone"
|
||||
134,"Queens","Kew Gardens","Boro Zone"
|
||||
135,"Queens","Kew Gardens Hills","Boro Zone"
|
||||
136,"Bronx","Kingsbridge Heights","Boro Zone"
|
||||
137,"Manhattan","Kips Bay","Yellow Zone"
|
||||
138,"Queens","LaGuardia Airport","Airports"
|
||||
139,"Queens","Laurelton","Boro Zone"
|
||||
140,"Manhattan","Lenox Hill East","Yellow Zone"
|
||||
141,"Manhattan","Lenox Hill West","Yellow Zone"
|
||||
142,"Manhattan","Lincoln Square East","Yellow Zone"
|
||||
143,"Manhattan","Lincoln Square West","Yellow Zone"
|
||||
144,"Manhattan","Little Italy/NoLiTa","Yellow Zone"
|
||||
145,"Queens","Long Island City/Hunters Point","Boro Zone"
|
||||
146,"Queens","Long Island City/Queens Plaza","Boro Zone"
|
||||
147,"Bronx","Longwood","Boro Zone"
|
||||
148,"Manhattan","Lower East Side","Yellow Zone"
|
||||
149,"Brooklyn","Madison","Boro Zone"
|
||||
150,"Brooklyn","Manhattan Beach","Boro Zone"
|
||||
151,"Manhattan","Manhattan Valley","Yellow Zone"
|
||||
152,"Manhattan","Manhattanville","Boro Zone"
|
||||
153,"Manhattan","Marble Hill","Boro Zone"
|
||||
154,"Brooklyn","Marine Park/Floyd Bennett Field","Boro Zone"
|
||||
155,"Brooklyn","Marine Park/Mill Basin","Boro Zone"
|
||||
156,"Staten Island","Mariners Harbor","Boro Zone"
|
||||
157,"Queens","Maspeth","Boro Zone"
|
||||
158,"Manhattan","Meatpacking/West Village West","Yellow Zone"
|
||||
159,"Bronx","Melrose South","Boro Zone"
|
||||
160,"Queens","Middle Village","Boro Zone"
|
||||
161,"Manhattan","Midtown Center","Yellow Zone"
|
||||
162,"Manhattan","Midtown East","Yellow Zone"
|
||||
163,"Manhattan","Midtown North","Yellow Zone"
|
||||
164,"Manhattan","Midtown South","Yellow Zone"
|
||||
165,"Brooklyn","Midwood","Boro Zone"
|
||||
166,"Manhattan","Morningside Heights","Boro Zone"
|
||||
167,"Bronx","Morrisania/Melrose","Boro Zone"
|
||||
168,"Bronx","Mott Haven/Port Morris","Boro Zone"
|
||||
169,"Bronx","Mount Hope","Boro Zone"
|
||||
170,"Manhattan","Murray Hill","Yellow Zone"
|
||||
171,"Queens","Murray Hill-Queens","Boro Zone"
|
||||
172,"Staten Island","New Dorp/Midland Beach","Boro Zone"
|
||||
173,"Queens","North Corona","Boro Zone"
|
||||
174,"Bronx","Norwood","Boro Zone"
|
||||
175,"Queens","Oakland Gardens","Boro Zone"
|
||||
176,"Staten Island","Oakwood","Boro Zone"
|
||||
177,"Brooklyn","Ocean Hill","Boro Zone"
|
||||
178,"Brooklyn","Ocean Parkway South","Boro Zone"
|
||||
179,"Queens","Old Astoria","Boro Zone"
|
||||
180,"Queens","Ozone Park","Boro Zone"
|
||||
181,"Brooklyn","Park Slope","Boro Zone"
|
||||
182,"Bronx","Parkchester","Boro Zone"
|
||||
183,"Bronx","Pelham Bay","Boro Zone"
|
||||
184,"Bronx","Pelham Bay Park","Boro Zone"
|
||||
185,"Bronx","Pelham Parkway","Boro Zone"
|
||||
186,"Manhattan","Penn Station/Madison Sq West","Yellow Zone"
|
||||
187,"Staten Island","Port Richmond","Boro Zone"
|
||||
188,"Brooklyn","Prospect-Lefferts Gardens","Boro Zone"
|
||||
189,"Brooklyn","Prospect Heights","Boro Zone"
|
||||
190,"Brooklyn","Prospect Park","Boro Zone"
|
||||
191,"Queens","Queens Village","Boro Zone"
|
||||
192,"Queens","Queensboro Hill","Boro Zone"
|
||||
193,"Queens","Queensbridge/Ravenswood","Boro Zone"
|
||||
194,"Manhattan","Randalls Island","Yellow Zone"
|
||||
195,"Brooklyn","Red Hook","Boro Zone"
|
||||
196,"Queens","Rego Park","Boro Zone"
|
||||
197,"Queens","Richmond Hill","Boro Zone"
|
||||
198,"Queens","Ridgewood","Boro Zone"
|
||||
199,"Bronx","Rikers Island","Boro Zone"
|
||||
200,"Bronx","Riverdale/North Riverdale/Fieldston","Boro Zone"
|
||||
201,"Queens","Rockaway Park","Boro Zone"
|
||||
202,"Manhattan","Roosevelt Island","Boro Zone"
|
||||
203,"Queens","Rosedale","Boro Zone"
|
||||
204,"Staten Island","Rossville/Woodrow","Boro Zone"
|
||||
205,"Queens","Saint Albans","Boro Zone"
|
||||
206,"Staten Island","Saint George/New Brighton","Boro Zone"
|
||||
207,"Queens","Saint Michaels Cemetery/Woodside","Boro Zone"
|
||||
208,"Bronx","Schuylerville/Edgewater Park","Boro Zone"
|
||||
209,"Manhattan","Seaport","Yellow Zone"
|
||||
210,"Brooklyn","Sheepshead Bay","Boro Zone"
|
||||
211,"Manhattan","SoHo","Yellow Zone"
|
||||
212,"Bronx","Soundview/Bruckner","Boro Zone"
|
||||
213,"Bronx","Soundview/Castle Hill","Boro Zone"
|
||||
214,"Staten Island","South Beach/Dongan Hills","Boro Zone"
|
||||
215,"Queens","South Jamaica","Boro Zone"
|
||||
216,"Queens","South Ozone Park","Boro Zone"
|
||||
217,"Brooklyn","South Williamsburg","Boro Zone"
|
||||
218,"Queens","Springfield Gardens North","Boro Zone"
|
||||
219,"Queens","Springfield Gardens South","Boro Zone"
|
||||
220,"Bronx","Spuyten Duyvil/Kingsbridge","Boro Zone"
|
||||
221,"Staten Island","Stapleton","Boro Zone"
|
||||
222,"Brooklyn","Starrett City","Boro Zone"
|
||||
223,"Queens","Steinway","Boro Zone"
|
||||
224,"Manhattan","Stuy Town/Peter Cooper Village","Yellow Zone"
|
||||
225,"Brooklyn","Stuyvesant Heights","Boro Zone"
|
||||
226,"Queens","Sunnyside","Boro Zone"
|
||||
227,"Brooklyn","Sunset Park East","Boro Zone"
|
||||
228,"Brooklyn","Sunset Park West","Boro Zone"
|
||||
229,"Manhattan","Sutton Place/Turtle Bay North","Yellow Zone"
|
||||
230,"Manhattan","Times Sq/Theatre District","Yellow Zone"
|
||||
231,"Manhattan","TriBeCa/Civic Center","Yellow Zone"
|
||||
232,"Manhattan","Two Bridges/Seward Park","Yellow Zone"
|
||||
233,"Manhattan","UN/Turtle Bay South","Yellow Zone"
|
||||
234,"Manhattan","Union Sq","Yellow Zone"
|
||||
235,"Bronx","University Heights/Morris Heights","Boro Zone"
|
||||
236,"Manhattan","Upper East Side North","Yellow Zone"
|
||||
237,"Manhattan","Upper East Side South","Yellow Zone"
|
||||
238,"Manhattan","Upper West Side North","Yellow Zone"
|
||||
239,"Manhattan","Upper West Side South","Yellow Zone"
|
||||
240,"Bronx","Van Cortlandt Park","Boro Zone"
|
||||
241,"Bronx","Van Cortlandt Village","Boro Zone"
|
||||
242,"Bronx","Van Nest/Morris Park","Boro Zone"
|
||||
243,"Manhattan","Washington Heights North","Boro Zone"
|
||||
244,"Manhattan","Washington Heights South","Boro Zone"
|
||||
245,"Staten Island","West Brighton","Boro Zone"
|
||||
246,"Manhattan","West Chelsea/Hudson Yards","Yellow Zone"
|
||||
247,"Bronx","West Concourse","Boro Zone"
|
||||
248,"Bronx","West Farms/Bronx River","Boro Zone"
|
||||
249,"Manhattan","West Village","Yellow Zone"
|
||||
250,"Bronx","Westchester Village/Unionport","Boro Zone"
|
||||
251,"Staten Island","Westerleigh","Boro Zone"
|
||||
252,"Queens","Whitestone","Boro Zone"
|
||||
253,"Queens","Willets Point","Boro Zone"
|
||||
254,"Bronx","Williamsbridge/Olinville","Boro Zone"
|
||||
255,"Brooklyn","Williamsburg (North Side)","Boro Zone"
|
||||
256,"Brooklyn","Williamsburg (South Side)","Boro Zone"
|
||||
257,"Brooklyn","Windsor Terrace","Boro Zone"
|
||||
258,"Queens","Woodhaven","Boro Zone"
|
||||
259,"Bronx","Woodlawn/Wakefield","Boro Zone"
|
||||
260,"Queens","Woodside","Boro Zone"
|
||||
261,"Manhattan","World Trade Center","Yellow Zone"
|
||||
262,"Manhattan","Yorkville East","Yellow Zone"
|
||||
263,"Manhattan","Yorkville West","Yellow Zone"
|
||||
264,"Unknown","NV","N/A"
|
||||
265,"Unknown","NA","N/A"
|
||||
"locationid","borough","zone","service_zone"
|
||||
1,"EWR","Newark Airport","EWR"
|
||||
2,"Queens","Jamaica Bay","Boro Zone"
|
||||
3,"Bronx","Allerton/Pelham Gardens","Boro Zone"
|
||||
4,"Manhattan","Alphabet City","Yellow Zone"
|
||||
5,"Staten Island","Arden Heights","Boro Zone"
|
||||
6,"Staten Island","Arrochar/Fort Wadsworth","Boro Zone"
|
||||
7,"Queens","Astoria","Boro Zone"
|
||||
8,"Queens","Astoria Park","Boro Zone"
|
||||
9,"Queens","Auburndale","Boro Zone"
|
||||
10,"Queens","Baisley Park","Boro Zone"
|
||||
11,"Brooklyn","Bath Beach","Boro Zone"
|
||||
12,"Manhattan","Battery Park","Yellow Zone"
|
||||
13,"Manhattan","Battery Park City","Yellow Zone"
|
||||
14,"Brooklyn","Bay Ridge","Boro Zone"
|
||||
15,"Queens","Bay Terrace/Fort Totten","Boro Zone"
|
||||
16,"Queens","Bayside","Boro Zone"
|
||||
17,"Brooklyn","Bedford","Boro Zone"
|
||||
18,"Bronx","Bedford Park","Boro Zone"
|
||||
19,"Queens","Bellerose","Boro Zone"
|
||||
20,"Bronx","Belmont","Boro Zone"
|
||||
21,"Brooklyn","Bensonhurst East","Boro Zone"
|
||||
22,"Brooklyn","Bensonhurst West","Boro Zone"
|
||||
23,"Staten Island","Bloomfield/Emerson Hill","Boro Zone"
|
||||
24,"Manhattan","Bloomingdale","Yellow Zone"
|
||||
25,"Brooklyn","Boerum Hill","Boro Zone"
|
||||
26,"Brooklyn","Borough Park","Boro Zone"
|
||||
27,"Queens","Breezy Point/Fort Tilden/Riis Beach","Boro Zone"
|
||||
28,"Queens","Briarwood/Jamaica Hills","Boro Zone"
|
||||
29,"Brooklyn","Brighton Beach","Boro Zone"
|
||||
30,"Queens","Broad Channel","Boro Zone"
|
||||
31,"Bronx","Bronx Park","Boro Zone"
|
||||
32,"Bronx","Bronxdale","Boro Zone"
|
||||
33,"Brooklyn","Brooklyn Heights","Boro Zone"
|
||||
34,"Brooklyn","Brooklyn Navy Yard","Boro Zone"
|
||||
35,"Brooklyn","Brownsville","Boro Zone"
|
||||
36,"Brooklyn","Bushwick North","Boro Zone"
|
||||
37,"Brooklyn","Bushwick South","Boro Zone"
|
||||
38,"Queens","Cambria Heights","Boro Zone"
|
||||
39,"Brooklyn","Canarsie","Boro Zone"
|
||||
40,"Brooklyn","Carroll Gardens","Boro Zone"
|
||||
41,"Manhattan","Central Harlem","Boro Zone"
|
||||
42,"Manhattan","Central Harlem North","Boro Zone"
|
||||
43,"Manhattan","Central Park","Yellow Zone"
|
||||
44,"Staten Island","Charleston/Tottenville","Boro Zone"
|
||||
45,"Manhattan","Chinatown","Yellow Zone"
|
||||
46,"Bronx","City Island","Boro Zone"
|
||||
47,"Bronx","Claremont/Bathgate","Boro Zone"
|
||||
48,"Manhattan","Clinton East","Yellow Zone"
|
||||
49,"Brooklyn","Clinton Hill","Boro Zone"
|
||||
50,"Manhattan","Clinton West","Yellow Zone"
|
||||
51,"Bronx","Co-Op City","Boro Zone"
|
||||
52,"Brooklyn","Cobble Hill","Boro Zone"
|
||||
53,"Queens","College Point","Boro Zone"
|
||||
54,"Brooklyn","Columbia Street","Boro Zone"
|
||||
55,"Brooklyn","Coney Island","Boro Zone"
|
||||
56,"Queens","Corona","Boro Zone"
|
||||
57,"Queens","Corona","Boro Zone"
|
||||
58,"Bronx","Country Club","Boro Zone"
|
||||
59,"Bronx","Crotona Park","Boro Zone"
|
||||
60,"Bronx","Crotona Park East","Boro Zone"
|
||||
61,"Brooklyn","Crown Heights North","Boro Zone"
|
||||
62,"Brooklyn","Crown Heights South","Boro Zone"
|
||||
63,"Brooklyn","Cypress Hills","Boro Zone"
|
||||
64,"Queens","Douglaston","Boro Zone"
|
||||
65,"Brooklyn","Downtown Brooklyn/MetroTech","Boro Zone"
|
||||
66,"Brooklyn","DUMBO/Vinegar Hill","Boro Zone"
|
||||
67,"Brooklyn","Dyker Heights","Boro Zone"
|
||||
68,"Manhattan","East Chelsea","Yellow Zone"
|
||||
69,"Bronx","East Concourse/Concourse Village","Boro Zone"
|
||||
70,"Queens","East Elmhurst","Boro Zone"
|
||||
71,"Brooklyn","East Flatbush/Farragut","Boro Zone"
|
||||
72,"Brooklyn","East Flatbush/Remsen Village","Boro Zone"
|
||||
73,"Queens","East Flushing","Boro Zone"
|
||||
74,"Manhattan","East Harlem North","Boro Zone"
|
||||
75,"Manhattan","East Harlem South","Boro Zone"
|
||||
76,"Brooklyn","East New York","Boro Zone"
|
||||
77,"Brooklyn","East New York/Pennsylvania Avenue","Boro Zone"
|
||||
78,"Bronx","East Tremont","Boro Zone"
|
||||
79,"Manhattan","East Village","Yellow Zone"
|
||||
80,"Brooklyn","East Williamsburg","Boro Zone"
|
||||
81,"Bronx","Eastchester","Boro Zone"
|
||||
82,"Queens","Elmhurst","Boro Zone"
|
||||
83,"Queens","Elmhurst/Maspeth","Boro Zone"
|
||||
84,"Staten Island","Eltingville/Annadale/Prince's Bay","Boro Zone"
|
||||
85,"Brooklyn","Erasmus","Boro Zone"
|
||||
86,"Queens","Far Rockaway","Boro Zone"
|
||||
87,"Manhattan","Financial District North","Yellow Zone"
|
||||
88,"Manhattan","Financial District South","Yellow Zone"
|
||||
89,"Brooklyn","Flatbush/Ditmas Park","Boro Zone"
|
||||
90,"Manhattan","Flatiron","Yellow Zone"
|
||||
91,"Brooklyn","Flatlands","Boro Zone"
|
||||
92,"Queens","Flushing","Boro Zone"
|
||||
93,"Queens","Flushing Meadows-Corona Park","Boro Zone"
|
||||
94,"Bronx","Fordham South","Boro Zone"
|
||||
95,"Queens","Forest Hills","Boro Zone"
|
||||
96,"Queens","Forest Park/Highland Park","Boro Zone"
|
||||
97,"Brooklyn","Fort Greene","Boro Zone"
|
||||
98,"Queens","Fresh Meadows","Boro Zone"
|
||||
99,"Staten Island","Freshkills Park","Boro Zone"
|
||||
100,"Manhattan","Garment District","Yellow Zone"
|
||||
101,"Queens","Glen Oaks","Boro Zone"
|
||||
102,"Queens","Glendale","Boro Zone"
|
||||
103,"Manhattan","Governor's Island/Ellis Island/Liberty Island","Yellow Zone"
|
||||
104,"Manhattan","Governor's Island/Ellis Island/Liberty Island","Yellow Zone"
|
||||
105,"Manhattan","Governor's Island/Ellis Island/Liberty Island","Yellow Zone"
|
||||
106,"Brooklyn","Gowanus","Boro Zone"
|
||||
107,"Manhattan","Gramercy","Yellow Zone"
|
||||
108,"Brooklyn","Gravesend","Boro Zone"
|
||||
109,"Staten Island","Great Kills","Boro Zone"
|
||||
110,"Staten Island","Great Kills Park","Boro Zone"
|
||||
111,"Brooklyn","Green-Wood Cemetery","Boro Zone"
|
||||
112,"Brooklyn","Greenpoint","Boro Zone"
|
||||
113,"Manhattan","Greenwich Village North","Yellow Zone"
|
||||
114,"Manhattan","Greenwich Village South","Yellow Zone"
|
||||
115,"Staten Island","Grymes Hill/Clifton","Boro Zone"
|
||||
116,"Manhattan","Hamilton Heights","Boro Zone"
|
||||
117,"Queens","Hammels/Arverne","Boro Zone"
|
||||
118,"Staten Island","Heartland Village/Todt Hill","Boro Zone"
|
||||
119,"Bronx","Highbridge","Boro Zone"
|
||||
120,"Manhattan","Highbridge Park","Boro Zone"
|
||||
121,"Queens","Hillcrest/Pomonok","Boro Zone"
|
||||
122,"Queens","Hollis","Boro Zone"
|
||||
123,"Brooklyn","Homecrest","Boro Zone"
|
||||
124,"Queens","Howard Beach","Boro Zone"
|
||||
125,"Manhattan","Hudson Sq","Yellow Zone"
|
||||
126,"Bronx","Hunts Point","Boro Zone"
|
||||
127,"Manhattan","Inwood","Boro Zone"
|
||||
128,"Manhattan","Inwood Hill Park","Boro Zone"
|
||||
129,"Queens","Jackson Heights","Boro Zone"
|
||||
130,"Queens","Jamaica","Boro Zone"
|
||||
131,"Queens","Jamaica Estates","Boro Zone"
|
||||
132,"Queens","JFK Airport","Airports"
|
||||
133,"Brooklyn","Kensington","Boro Zone"
|
||||
134,"Queens","Kew Gardens","Boro Zone"
|
||||
135,"Queens","Kew Gardens Hills","Boro Zone"
|
||||
136,"Bronx","Kingsbridge Heights","Boro Zone"
|
||||
137,"Manhattan","Kips Bay","Yellow Zone"
|
||||
138,"Queens","LaGuardia Airport","Airports"
|
||||
139,"Queens","Laurelton","Boro Zone"
|
||||
140,"Manhattan","Lenox Hill East","Yellow Zone"
|
||||
141,"Manhattan","Lenox Hill West","Yellow Zone"
|
||||
142,"Manhattan","Lincoln Square East","Yellow Zone"
|
||||
143,"Manhattan","Lincoln Square West","Yellow Zone"
|
||||
144,"Manhattan","Little Italy/NoLiTa","Yellow Zone"
|
||||
145,"Queens","Long Island City/Hunters Point","Boro Zone"
|
||||
146,"Queens","Long Island City/Queens Plaza","Boro Zone"
|
||||
147,"Bronx","Longwood","Boro Zone"
|
||||
148,"Manhattan","Lower East Side","Yellow Zone"
|
||||
149,"Brooklyn","Madison","Boro Zone"
|
||||
150,"Brooklyn","Manhattan Beach","Boro Zone"
|
||||
151,"Manhattan","Manhattan Valley","Yellow Zone"
|
||||
152,"Manhattan","Manhattanville","Boro Zone"
|
||||
153,"Manhattan","Marble Hill","Boro Zone"
|
||||
154,"Brooklyn","Marine Park/Floyd Bennett Field","Boro Zone"
|
||||
155,"Brooklyn","Marine Park/Mill Basin","Boro Zone"
|
||||
156,"Staten Island","Mariners Harbor","Boro Zone"
|
||||
157,"Queens","Maspeth","Boro Zone"
|
||||
158,"Manhattan","Meatpacking/West Village West","Yellow Zone"
|
||||
159,"Bronx","Melrose South","Boro Zone"
|
||||
160,"Queens","Middle Village","Boro Zone"
|
||||
161,"Manhattan","Midtown Center","Yellow Zone"
|
||||
162,"Manhattan","Midtown East","Yellow Zone"
|
||||
163,"Manhattan","Midtown North","Yellow Zone"
|
||||
164,"Manhattan","Midtown South","Yellow Zone"
|
||||
165,"Brooklyn","Midwood","Boro Zone"
|
||||
166,"Manhattan","Morningside Heights","Boro Zone"
|
||||
167,"Bronx","Morrisania/Melrose","Boro Zone"
|
||||
168,"Bronx","Mott Haven/Port Morris","Boro Zone"
|
||||
169,"Bronx","Mount Hope","Boro Zone"
|
||||
170,"Manhattan","Murray Hill","Yellow Zone"
|
||||
171,"Queens","Murray Hill-Queens","Boro Zone"
|
||||
172,"Staten Island","New Dorp/Midland Beach","Boro Zone"
|
||||
173,"Queens","North Corona","Boro Zone"
|
||||
174,"Bronx","Norwood","Boro Zone"
|
||||
175,"Queens","Oakland Gardens","Boro Zone"
|
||||
176,"Staten Island","Oakwood","Boro Zone"
|
||||
177,"Brooklyn","Ocean Hill","Boro Zone"
|
||||
178,"Brooklyn","Ocean Parkway South","Boro Zone"
|
||||
179,"Queens","Old Astoria","Boro Zone"
|
||||
180,"Queens","Ozone Park","Boro Zone"
|
||||
181,"Brooklyn","Park Slope","Boro Zone"
|
||||
182,"Bronx","Parkchester","Boro Zone"
|
||||
183,"Bronx","Pelham Bay","Boro Zone"
|
||||
184,"Bronx","Pelham Bay Park","Boro Zone"
|
||||
185,"Bronx","Pelham Parkway","Boro Zone"
|
||||
186,"Manhattan","Penn Station/Madison Sq West","Yellow Zone"
|
||||
187,"Staten Island","Port Richmond","Boro Zone"
|
||||
188,"Brooklyn","Prospect-Lefferts Gardens","Boro Zone"
|
||||
189,"Brooklyn","Prospect Heights","Boro Zone"
|
||||
190,"Brooklyn","Prospect Park","Boro Zone"
|
||||
191,"Queens","Queens Village","Boro Zone"
|
||||
192,"Queens","Queensboro Hill","Boro Zone"
|
||||
193,"Queens","Queensbridge/Ravenswood","Boro Zone"
|
||||
194,"Manhattan","Randalls Island","Yellow Zone"
|
||||
195,"Brooklyn","Red Hook","Boro Zone"
|
||||
196,"Queens","Rego Park","Boro Zone"
|
||||
197,"Queens","Richmond Hill","Boro Zone"
|
||||
198,"Queens","Ridgewood","Boro Zone"
|
||||
199,"Bronx","Rikers Island","Boro Zone"
|
||||
200,"Bronx","Riverdale/North Riverdale/Fieldston","Boro Zone"
|
||||
201,"Queens","Rockaway Park","Boro Zone"
|
||||
202,"Manhattan","Roosevelt Island","Boro Zone"
|
||||
203,"Queens","Rosedale","Boro Zone"
|
||||
204,"Staten Island","Rossville/Woodrow","Boro Zone"
|
||||
205,"Queens","Saint Albans","Boro Zone"
|
||||
206,"Staten Island","Saint George/New Brighton","Boro Zone"
|
||||
207,"Queens","Saint Michaels Cemetery/Woodside","Boro Zone"
|
||||
208,"Bronx","Schuylerville/Edgewater Park","Boro Zone"
|
||||
209,"Manhattan","Seaport","Yellow Zone"
|
||||
210,"Brooklyn","Sheepshead Bay","Boro Zone"
|
||||
211,"Manhattan","SoHo","Yellow Zone"
|
||||
212,"Bronx","Soundview/Bruckner","Boro Zone"
|
||||
213,"Bronx","Soundview/Castle Hill","Boro Zone"
|
||||
214,"Staten Island","South Beach/Dongan Hills","Boro Zone"
|
||||
215,"Queens","South Jamaica","Boro Zone"
|
||||
216,"Queens","South Ozone Park","Boro Zone"
|
||||
217,"Brooklyn","South Williamsburg","Boro Zone"
|
||||
218,"Queens","Springfield Gardens North","Boro Zone"
|
||||
219,"Queens","Springfield Gardens South","Boro Zone"
|
||||
220,"Bronx","Spuyten Duyvil/Kingsbridge","Boro Zone"
|
||||
221,"Staten Island","Stapleton","Boro Zone"
|
||||
222,"Brooklyn","Starrett City","Boro Zone"
|
||||
223,"Queens","Steinway","Boro Zone"
|
||||
224,"Manhattan","Stuy Town/Peter Cooper Village","Yellow Zone"
|
||||
225,"Brooklyn","Stuyvesant Heights","Boro Zone"
|
||||
226,"Queens","Sunnyside","Boro Zone"
|
||||
227,"Brooklyn","Sunset Park East","Boro Zone"
|
||||
228,"Brooklyn","Sunset Park West","Boro Zone"
|
||||
229,"Manhattan","Sutton Place/Turtle Bay North","Yellow Zone"
|
||||
230,"Manhattan","Times Sq/Theatre District","Yellow Zone"
|
||||
231,"Manhattan","TriBeCa/Civic Center","Yellow Zone"
|
||||
232,"Manhattan","Two Bridges/Seward Park","Yellow Zone"
|
||||
233,"Manhattan","UN/Turtle Bay South","Yellow Zone"
|
||||
234,"Manhattan","Union Sq","Yellow Zone"
|
||||
235,"Bronx","University Heights/Morris Heights","Boro Zone"
|
||||
236,"Manhattan","Upper East Side North","Yellow Zone"
|
||||
237,"Manhattan","Upper East Side South","Yellow Zone"
|
||||
238,"Manhattan","Upper West Side North","Yellow Zone"
|
||||
239,"Manhattan","Upper West Side South","Yellow Zone"
|
||||
240,"Bronx","Van Cortlandt Park","Boro Zone"
|
||||
241,"Bronx","Van Cortlandt Village","Boro Zone"
|
||||
242,"Bronx","Van Nest/Morris Park","Boro Zone"
|
||||
243,"Manhattan","Washington Heights North","Boro Zone"
|
||||
244,"Manhattan","Washington Heights South","Boro Zone"
|
||||
245,"Staten Island","West Brighton","Boro Zone"
|
||||
246,"Manhattan","West Chelsea/Hudson Yards","Yellow Zone"
|
||||
247,"Bronx","West Concourse","Boro Zone"
|
||||
248,"Bronx","West Farms/Bronx River","Boro Zone"
|
||||
249,"Manhattan","West Village","Yellow Zone"
|
||||
250,"Bronx","Westchester Village/Unionport","Boro Zone"
|
||||
251,"Staten Island","Westerleigh","Boro Zone"
|
||||
252,"Queens","Whitestone","Boro Zone"
|
||||
253,"Queens","Willets Point","Boro Zone"
|
||||
254,"Bronx","Williamsbridge/Olinville","Boro Zone"
|
||||
255,"Brooklyn","Williamsburg (North Side)","Boro Zone"
|
||||
256,"Brooklyn","Williamsburg (South Side)","Boro Zone"
|
||||
257,"Brooklyn","Windsor Terrace","Boro Zone"
|
||||
258,"Queens","Woodhaven","Boro Zone"
|
||||
259,"Bronx","Woodlawn/Wakefield","Boro Zone"
|
||||
260,"Queens","Woodside","Boro Zone"
|
||||
261,"Manhattan","World Trade Center","Yellow Zone"
|
||||
262,"Manhattan","Yorkville East","Yellow Zone"
|
||||
263,"Manhattan","Yorkville West","Yellow Zone"
|
||||
264,"Unknown","NV","N/A"
|
||||
265,"Unknown","NA","N/A"
|
||||
|
122
05-batch/README.md
Normal file
122
05-batch/README.md
Normal file
@ -0,0 +1,122 @@
|
||||
# Week 5: Batch Processing
|
||||
|
||||
## 5.1 Introduction
|
||||
|
||||
* :movie_camera: 5.1.1 Introduction to Batch Processing
|
||||
|
||||
[](https://youtu.be/dcHe5Fl3MF8&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=51)
|
||||
|
||||
* :movie_camera: 5.1.2 Introduction to Spark
|
||||
|
||||
[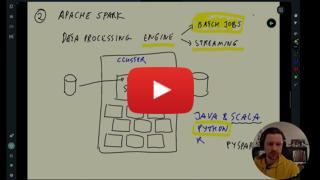](https://youtu.be/FhaqbEOuQ8U&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=52)
|
||||
|
||||
|
||||
## 5.2 Installation
|
||||
|
||||
Follow [these intructions](setup/) to install Spark:
|
||||
|
||||
* [Windows](setup/windows.md)
|
||||
* [Linux](setup/linux.md)
|
||||
* [MacOS](setup/macos.md)
|
||||
|
||||
And follow [this](setup/pyspark.md) to run PySpark in Jupyter
|
||||
|
||||
* :movie_camera: 5.2.1 (Optional) Installing Spark (Linux)
|
||||
|
||||
[](https://youtu.be/hqUbB9c8sKg&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=53)
|
||||
|
||||
Alternatively, if the setups above don't work, you can run Spark in Google Colab.
|
||||
> [!NOTE]
|
||||
> It's advisable to invest some time in setting things up locally rather than immediately jumping into this solution
|
||||
|
||||
* [Google Colab Instructions](https://medium.com/gitconnected/launch-spark-on-google-colab-and-connect-to-sparkui-342cad19b304)
|
||||
* [Google Colab Starter Notebook](https://github.com/aaalexlit/medium_articles/blob/main/Spark_in_Colab.ipynb)
|
||||
|
||||
|
||||
## 5.3 Spark SQL and DataFrames
|
||||
|
||||
* :movie_camera: 5.3.1 First Look at Spark/PySpark
|
||||
|
||||
[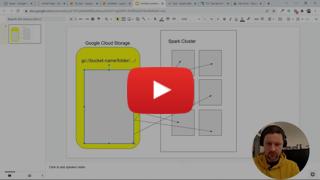](https://youtu.be/r_Sf6fCB40c&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=54)
|
||||
|
||||
* :movie_camera: 5.3.2 Spark Dataframes
|
||||
|
||||
[](https://youtu.be/ti3aC1m3rE8&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=55)
|
||||
|
||||
* :movie_camera: 5.3.3 (Optional) Preparing Yellow and Green Taxi Data
|
||||
|
||||
[](https://youtu.be/CI3P4tAtru4&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=56)
|
||||
|
||||
Script to prepare the Dataset [download_data.sh](code/download_data.sh)
|
||||
|
||||
> [!NOTE]
|
||||
> The other way to infer the schema (apart from pandas) for the csv files, is to set the `inferSchema` option to `true` while reading the files in Spark.
|
||||
|
||||
* :movie_camera: 5.3.4 SQL with Spark
|
||||
|
||||
[](https://youtu.be/uAlp2VuZZPY&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=57)
|
||||
|
||||
|
||||
## 5.4 Spark Internals
|
||||
|
||||
* :movie_camera: 5.4.1 Anatomy of a Spark Cluster
|
||||
|
||||
[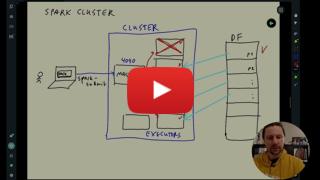](https://youtu.be/68CipcZt7ZA&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=58)
|
||||
|
||||
* :movie_camera: 5.4.2 GroupBy in Spark
|
||||
|
||||
[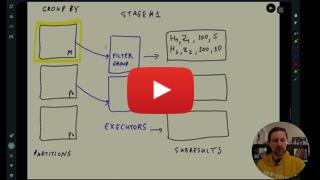](https://youtu.be/9qrDsY_2COo&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=59)
|
||||
|
||||
* :movie_camera: 5.4.3 Joins in Spark
|
||||
|
||||
[](https://youtu.be/lu7TrqAWuH4&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=60)
|
||||
|
||||
## 5.5 (Optional) Resilient Distributed Datasets
|
||||
|
||||
* :movie_camera: 5.5.1 Operations on Spark RDDs
|
||||
|
||||
[](https://youtu.be/Bdu-xIrF3OM&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=61)
|
||||
|
||||
* :movie_camera: 5.5.2 Spark RDD mapPartition
|
||||
|
||||
[](https://youtu.be/k3uB2K99roI&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=62)
|
||||
|
||||
|
||||
## 5.6 Running Spark in the Cloud
|
||||
|
||||
* :movie_camera: 5.6.1 Connecting to Google Cloud Storage
|
||||
|
||||
[](https://youtu.be/Yyz293hBVcQ&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=63)
|
||||
|
||||
* :movie_camera: 5.6.2 Creating a Local Spark Cluster
|
||||
|
||||
[](https://youtu.be/HXBwSlXo5IA&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=64)
|
||||
|
||||
* :movie_camera: 5.6.3 Setting up a Dataproc Cluster
|
||||
|
||||
[](https://youtu.be/osAiAYahvh8&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=65)
|
||||
|
||||
* :movie_camera: 5.6.4 Connecting Spark to Big Query
|
||||
|
||||
[](https://youtu.be/HIm2BOj8C0Q&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=66)
|
||||
|
||||
|
||||
# Homework
|
||||
|
||||
* [2024 Homework](../cohorts/2024/05-batch/homework.md)
|
||||
|
||||
|
||||
# Community notes
|
||||
|
||||
Did you take notes? You can share them here.
|
||||
|
||||
* [Notes by Alvaro Navas](https://github.com/ziritrion/dataeng-zoomcamp/blob/main/notes/5_batch_processing.md)
|
||||
* [Sandy's DE Learning Blog](https://learningdataengineering540969211.wordpress.com/2022/02/24/week-5-de-zoomcamp-5-2-1-installing-spark-on-linux/)
|
||||
* [Notes by Alain Boisvert](https://github.com/boisalai/de-zoomcamp-2023/blob/main/week5.md)
|
||||
* [Alternative : Using docker-compose to launch spark by rafik](https://gist.github.com/rafik-rahoui/f98df941c4ccced9c46e9ccbdef63a03)
|
||||
* [Marcos Torregrosa's blog (spanish)](https://www.n4gash.com/2023/data-engineering-zoomcamp-semana-5-batch-spark)
|
||||
* [Notes by Victor Padilha](https://github.com/padilha/de-zoomcamp/tree/master/week5)
|
||||
* [Notes by Oscar Garcia](https://github.com/ozkary/Data-Engineering-Bootcamp/tree/main/Step5-Batch-Processing)
|
||||
* [Notes by HongWei](https://github.com/hwchua0209/data-engineering-zoomcamp-submission/blob/main/05-batch-processing/README.md)
|
||||
* [2024 videos transcript](https://drive.google.com/drive/folders/1XMmP4H5AMm1qCfMFxc_hqaPGw31KIVcb?usp=drive_link) by Maria Fisher
|
||||
* Add your notes here (above this line)
|
||||
@ -65,7 +65,17 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"!wget https://nyc-tlc.s3.amazonaws.com/trip+data/fhvhv_tripdata_2021-01.csv"
|
||||
"!wget https://github.com/DataTalksClub/nyc-tlc-data/releases/download/fhvhv/fhvhv_tripdata_2021-01.csv.gz"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "201a5957",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"!gzip -dc fhvhv_tripdata_2021-01.csv.gz"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -501,25 +511,25 @@
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"hvfhs_license_num,dispatching_base_num,pickup_datetime,dropoff_datetime,PULocationID,DOLocationID,SR_Flag\r",
|
||||
"hvfhs_license_num,dispatching_base_num,pickup_datetime,dropoff_datetime,PULocationID,DOLocationID,SR_Flag\r\n",
|
||||
"\r\n",
|
||||
"HV0003,B02682,2021-01-01 00:33:44,2021-01-01 00:49:07,230,166,\r",
|
||||
"HV0003,B02682,2021-01-01 00:33:44,2021-01-01 00:49:07,230,166,\r\n",
|
||||
"\r\n",
|
||||
"HV0003,B02682,2021-01-01 00:55:19,2021-01-01 01:18:21,152,167,\r",
|
||||
"HV0003,B02682,2021-01-01 00:55:19,2021-01-01 01:18:21,152,167,\r\n",
|
||||
"\r\n",
|
||||
"HV0003,B02764,2021-01-01 00:23:56,2021-01-01 00:38:05,233,142,\r",
|
||||
"HV0003,B02764,2021-01-01 00:23:56,2021-01-01 00:38:05,233,142,\r\n",
|
||||
"\r\n",
|
||||
"HV0003,B02764,2021-01-01 00:42:51,2021-01-01 00:45:50,142,143,\r",
|
||||
"HV0003,B02764,2021-01-01 00:42:51,2021-01-01 00:45:50,142,143,\r\n",
|
||||
"\r\n",
|
||||
"HV0003,B02764,2021-01-01 00:48:14,2021-01-01 01:08:42,143,78,\r",
|
||||
"HV0003,B02764,2021-01-01 00:48:14,2021-01-01 01:08:42,143,78,\r\n",
|
||||
"\r\n",
|
||||
"HV0005,B02510,2021-01-01 00:06:59,2021-01-01 00:43:01,88,42,\r",
|
||||
"HV0005,B02510,2021-01-01 00:06:59,2021-01-01 00:43:01,88,42,\r\n",
|
||||
"\r\n",
|
||||
"HV0005,B02510,2021-01-01 00:50:00,2021-01-01 01:04:57,42,151,\r",
|
||||
"HV0005,B02510,2021-01-01 00:50:00,2021-01-01 01:04:57,42,151,\r\n",
|
||||
"\r\n",
|
||||
"HV0003,B02764,2021-01-01 00:14:30,2021-01-01 00:50:27,71,226,\r",
|
||||
"HV0003,B02764,2021-01-01 00:14:30,2021-01-01 00:50:27,71,226,\r\n",
|
||||
"\r\n",
|
||||
"HV0003,B02875,2021-01-01 00:22:54,2021-01-01 00:30:20,112,255,\r",
|
||||
"HV0003,B02875,2021-01-01 00:22:54,2021-01-01 00:30:20,112,255,\r\n",
|
||||
"\r\n"
|
||||
]
|
||||
}
|
||||
@ -57,8 +57,7 @@ rm openjdk-11.0.2_linux-x64_bin.tar.gz
|
||||
Download Spark. Use 3.3.2 version:
|
||||
|
||||
```bash
|
||||
wget https://dlcdn.apache.org/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz
|
||||
|
||||
wget https://archive.apache.org/dist/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz
|
||||
```
|
||||
|
||||
Unpack:
|
||||
@ -10,7 +10,7 @@ for other MacOS versions as well
|
||||
Ensure Brew and Java installed in your system:
|
||||
|
||||
```bash
|
||||
xcode-select –install
|
||||
xcode-select --install
|
||||
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"
|
||||
brew install java
|
||||
```
|
||||
@ -24,6 +24,31 @@ export PATH="$JAVA_HOME/bin/:$PATH"
|
||||
|
||||
Make sure Java was installed to `/usr/local/Cellar/openjdk@11/11.0.12`: Open Finder > Press Cmd+Shift+G > paste "/usr/local/Cellar/openjdk@11/11.0.12". If you can't find it, then change the path location to appropriate path on your machine. You can also run `brew info java` to check where java was installed on your machine.
|
||||
|
||||
### Anaconda-based spark set up
|
||||
if you are having anaconda setup, you can skip the spark installation and instead Pyspark package to run the spark.
|
||||
With Anaconda and Mac we can spark set by first installing pyspark and then for environment variable set up findspark
|
||||
|
||||
Open Anaconda Activate the environment where you want to apply these changes
|
||||
|
||||
Run pyspark and install it as a package in this environment <br>
|
||||
Run findspark and install it as a package in this environment
|
||||
|
||||
Ensure that open JDK is already set up. This allows us to not have to install Spark separately and manually set up the environment Also with this we may have to use Jupyter Lab (instead of Jupyter Notebook) to open a Jupyter notebook for running the programs.
|
||||
Once the Spark is set up start the conda environment and open Jupyter Lab.
|
||||
Run the program below in notebook to check everything is running fine.
|
||||
```
|
||||
import pyspark
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
!spark-shell --version
|
||||
|
||||
# Create SparkSession
|
||||
spark = SparkSession.builder.master("local[1]") \
|
||||
.appName('test-spark') \
|
||||
.getOrCreate()
|
||||
|
||||
print(f'The PySpark {spark.version} version is running...')
|
||||
```
|
||||
### Installing Spark
|
||||
|
||||
1. Install Scala
|
||||
@ -64,3 +89,4 @@ distData.filter(_ < 10).collect()
|
||||
It's the same for all platforms. Go to [pyspark.md](pyspark.md).
|
||||
|
||||
|
||||
|
||||
@ -68,7 +68,7 @@ export PATH="${HADOOP_HOME}/bin:${PATH}"
|
||||
Now download Spark. Select version 3.3.2
|
||||
|
||||
```bash
|
||||
wget https://dlcdn.apache.org/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz
|
||||
wget https://archive.apache.org/dist/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz
|
||||
```
|
||||
|
||||
|
||||
129
06-streaming/README.md
Normal file
129
06-streaming/README.md
Normal file
@ -0,0 +1,129 @@
|
||||
# Week 6: Stream Processing
|
||||
|
||||
# Code structure
|
||||
* [Java examples](java)
|
||||
* [Python examples](python)
|
||||
* [KSQLD examples](ksqldb)
|
||||
|
||||
## Confluent cloud setup
|
||||
Confluent cloud provides a free 30 days trial for, you can signup [here](https://www.confluent.io/confluent-cloud/tryfree/)
|
||||
|
||||
## Introduction to Stream Processing
|
||||
|
||||
- [Slides](https://docs.google.com/presentation/d/1bCtdCba8v1HxJ_uMm9pwjRUC-NAMeB-6nOG2ng3KujA/edit?usp=sharing)
|
||||
|
||||
- :movie_camera: 6.0.1 Introduction
|
||||
|
||||
[](https://youtu.be/hfvju3iOIP0&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=67)
|
||||
|
||||
- :movie_camera: 6.0.2 What is stream processing
|
||||
|
||||
[](https://youtu.be/WxTxKGcfA-k&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=68)
|
||||
|
||||
## Introduction to Kafka
|
||||
|
||||
- :movie_camera: 6.3 What is kafka?
|
||||
|
||||
[](https://youtu.be/zPLZUDPi4AY&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=69)
|
||||
|
||||
- :movie_camera: 6.4 Confluent cloud
|
||||
|
||||
[](https://youtu.be/ZnEZFEYKppw&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=70)
|
||||
|
||||
- :movie_camera: 6.5 Kafka producer consumer
|
||||
|
||||
[](https://youtu.be/aegTuyxX7Yg&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=71)
|
||||
|
||||
## Kafka Configuration
|
||||
|
||||
- :movie_camera: 6.6 Kafka configuration
|
||||
|
||||
[](https://youtu.be/SXQtWyRpMKs&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=72)
|
||||
|
||||
- [Kafka Configuration Reference](https://docs.confluent.io/platform/current/installation/configuration/)
|
||||
|
||||
## Kafka Streams
|
||||
|
||||
- [Slides](https://docs.google.com/presentation/d/1fVi9sFa7fL2ZW3ynS5MAZm0bRSZ4jO10fymPmrfTUjE/edit?usp=sharing)
|
||||
|
||||
- [Streams Concepts](https://docs.confluent.io/platform/current/streams/concepts.html)
|
||||
|
||||
- :movie_camera: 6.7 Kafka streams basics
|
||||
|
||||
[](https://youtu.be/dUyA_63eRb0&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=73)
|
||||
|
||||
- :movie_camera: 6.8 Kafka stream join
|
||||
|
||||
[](https://youtu.be/NcpKlujh34Y&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=74)
|
||||
|
||||
- :movie_camera: 6.9 Kafka stream testing
|
||||
|
||||
[](https://youtu.be/TNx5rmLY8Pk&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=75)
|
||||
|
||||
- :movie_camera: 6.10 Kafka stream windowing
|
||||
|
||||
[](https://youtu.be/r1OuLdwxbRc&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=76)
|
||||
|
||||
- :movie_camera: 6.11 Kafka ksqldb & Connect
|
||||
|
||||
[](https://youtu.be/DziQ4a4tn9Y&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=77)
|
||||
|
||||
- :movie_camera: 6.12 Kafka Schema registry
|
||||
|
||||
[](https://youtu.be/tBY_hBuyzwI&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=78)
|
||||
|
||||
## Faust - Python Stream Processing
|
||||
|
||||
- [Faust Documentation](https://faust.readthedocs.io/en/latest/index.html)
|
||||
- [Faust vs Kafka Streams](https://faust.readthedocs.io/en/latest/playbooks/vskafka.html)
|
||||
|
||||
## Pyspark - Structured Streaming
|
||||
Please follow the steps described under [pyspark-streaming](python/streams-example/pyspark/README.md)
|
||||
|
||||
- :movie_camera: 6.13 Kafka Streaming with Python
|
||||
|
||||
[](https://youtu.be/BgAlVknDFlQ&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=79)
|
||||
|
||||
- :movie_camera: 6.14 Pyspark Structured Streaming
|
||||
|
||||
[](https://youtu.be/VIVr7KwRQmE&list=PL3MmuxUbc_hJed7dXYoJw8DoCuVHhGEQb&index=80)
|
||||
|
||||
## Kafka Streams with JVM library
|
||||
|
||||
- [Confluent Kafka Streams](https://kafka.apache.org/documentation/streams/)
|
||||
- [Scala Example](https://github.com/AnkushKhanna/kafka-helper/tree/master/src/main/scala/kafka/schematest)
|
||||
|
||||
## KSQL and ksqlDB
|
||||
|
||||
- [Introducing KSQL: Streaming SQL for Apache Kafka](https://www.confluent.io/blog/ksql-streaming-sql-for-apache-kafka/)
|
||||
- [ksqlDB](https://ksqldb.io/)
|
||||
|
||||
## Kafka Connect
|
||||
|
||||
- [Making Sense of Stream Data](https://medium.com/analytics-vidhya/making-sense-of-stream-data-b74c1252a8f5)
|
||||
|
||||
## Docker
|
||||
|
||||
### Starting cluster
|
||||
|
||||
## Command line for Kafka
|
||||
|
||||
### Create topic
|
||||
|
||||
```bash
|
||||
./bin/kafka-topics.sh --create --topic demo_1 --bootstrap-server localhost:9092 --partitions 2
|
||||
```
|
||||
|
||||
## Homework
|
||||
|
||||
* [2024 Homework](../cohorts/2024/)
|
||||
|
||||
## Community notes
|
||||
|
||||
Did you take notes? You can share them here.
|
||||
|
||||
* [Notes by Alvaro Navas](https://github.com/ziritrion/dataeng-zoomcamp/blob/main/notes/6_streaming.md )
|
||||
* [Marcos Torregrosa's blog (spanish)](https://www.n4gash.com/2023/data-engineering-zoomcamp-semana-6-stream-processing/)
|
||||
* [Notes by Oscar Garcia](https://github.com/ozkary/Data-Engineering-Bootcamp/tree/main/Step6-Streaming)
|
||||
* Add your notes here (above this line)
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user